Gemini
24 февраля 2026 г.
Gemini 3.1 Pro: обзор, бенчмарки, сравнение
Прогремел очередной релиз, Google DeepMind 19 февраля 2026 года выпустила свою новую модель - Gemini 3.1 Pro.Это стало неожиданностью даже для искушенного ИИ-сообщества. Обычно Google обновлял версии с шагом 0.5 (1.0 - 1.5 - 2.0 - 2.5 - 3.0), но здесь мы впервые видим обновление 3.1. И это при том, что предыдущая версия (Gemini 3 Pro) до сих пор носит гордую приставку Preview и так и не вышла в полноценный релиз. Согласитесь, немного похоже на ситуацию, когда вы ещё не допили чай, а вам уже наливают новую кружку, утверждая, что она горячее.Но Google явно знает, что делает. Компания заявляет, что 3.1 Pro - это не просто косметическое обновление, а шаг вперёд в фундаментальных рассуждениях. Модель создана для решения задач, где простого ответа недостаточно, и ориентирована на агентные рабочие процессы и глубокое планирование.

Возможности модели. Что нам обещают (и не обещают) разработчики
Google не стал мелочиться и назвал Gemini 3.1 Pro своей самой интеллектуальной моделью для сложных задач. Звучит гордо, но давайте посмотрим, что стоит за этими словами.Ключевое улучшение - ядро интеллектаГлавная фишка апдейта - это улучшенное базовое мышление. Если прошлые обновления Gemini 3 Pro были больше про расширение возможностей, то здесь инженеры Google DeepMind занялись прокачкой внутреннего процессора модели. Фактически, технология глубокого мышления, которую на прошлой неделе добавили в отдельный режим, теперь интегрирована прямо в основу модели. Это значит, что 3.1 Pro умеет думать над задачей дольше и качественнее, прокладывая несколько путей решения одновременно, а потом выбирая лучший.Зачем это нужно? Как говорят в Google, для задач, где простого ответа недостаточно. Представьте, что вы просите нейросеть не просто пересказать статью из Википедии, а проанализировать несколько противоречивых научных работ и сделать обоснованный вывод. Вот для такого ей и нужны эти улучшенные мозги.Мультимодальность и контекст: смотрим, слушаем, читаемПо части органов чувств у модели всё осталось на уровне топ-флагмана. Она понимает текст, изображения, видео, аудио и PDF-файлы.Контекстное окно - те же 1 миллион токенов на входе. Для тех, кто не в теме: это примерно как «Война и мир», которую вы можете загрузить и задавать вопросы. На выходе модель выдает до 64 тысяч токенов. То есть она способна сгенерировать целую небольшую повесть или очень объемный кусок кода.Кстати, про код. Разработчики утверждают, что 3.1 Pro специально оптимизирована для задач программирования и агентных рабочих процессов. Это когда вы даете ей не один запрос, а цепочку: «сделай это, потом на основе результата сделай то, и если увидишь ошибку - исправь».Цифры, которые впечатляют (и которые стоит проверить)
Google традиционно приводит результаты бенчмарков. Вот где обещанное мышление проявило себя лучше всего:- ARC-AGI-2 - тест на способность решать новые, нестандартные логические задачи без опоры на шаблоны. Тут Gemini 3.1 Pro набрал 77,1%. Это более чем в два раза выше, чем у Gemini 3 Pro (31,1%). Рост, который сложно не заметить.
- Humanity's Last Exam - проверка знаний в узкоспециализированных областях, где модель показала 44,4% . Для сравнения: Gemini 3 Pro было 37,5%, а GPT-5.2 - 34,5% .

Не только цифры. Что модель умеет делать руками (вернее, кодом)
Google не был бы Google, если бы не показал красивые демо. Они выкатили несколько примеров, наглядно демонстрирующих, зачем нужна такая умная модель:Литература - веб-дизайнМодель проанализировала роман «Грозовой перевал» и на основе его атмосферы сгенерировала полноценный сайт-портфолио для вымышленного фотографа. Дизайн реально передает мрачновато-романтическое настроение книги. Интерактивная 3D-симуляцияОна написала код, который создаёт симуляцию полета стаи птиц (моделирование сложных систем). И это не просто картинка - пользователь может мышкой влиять на траекторию полёта, а звуковой фон меняется в зависимости от плотности стаи.Аэрокосмический дашбордМодель подключилась к открытому API, получает данные о местоположении МКС в реальном времени и строит интерактивную карту с траекторией полёта. Прямо как в центре управления полётами, только на коленке за пять минут.Анимированные SVGИз текстового описания вроде “анимированная иконка загрузки в стиле киберпанк” модель генерирует чистый код анимации, который можно сразу вставить на сайт.Нюансы и мелкий шрифтРазработчики, как всегда, честно предупреждают о некоторых особенностях. Это preview-версия, находящаяся в стадии предварительного доступа. Google выпустил её для проверки обновлений и усовершенствований, поэтому баги возможны. Если вы используете специализированный эндпоинт gemini-3.1-pro-preview-customtools и предоставляете модели свои инструменты, такие как view_file или search_code, её работа будет лучше. Однако без инструментов качество ответов может варьироваться. Модель не генерирует изображения, не работает с Live API и не умеет привязываться к Google Maps, но может написать код для отрисовки картинки. Знания модели актуальны до января 2025 года, поэтому спрашивать о последних мемах февраля 2026 года бессмысленно.Что в сухом остаткеGemini 3.1 Pro - это попытка Google сделать инструмент для решения сложных, многошаговых задач. Основной упор сделан на качество рассуждений и способность модели действовать как агент, а не просто отвечать на запросы. Технические характеристики (контекст, мультимодальность) остались на уровне топ-моделей, а вот мозги ей действительно подкрутили.Тестирование на заданиях: код, математика и сказки на ночь
Официальные бенчмарки - это, конечно, красиво. 77,1% в ARC-AGI-2 звучит внушительно. Но как говорится, доверяй, но проверяй. Тем более что тесты вроде Humanity's Last Exam хоть и сложные, но всё равно остаются тестами. Мне было интересно другое. Как модель поведёт себя в реальных, почти бытовых задачах, с которыми сталкивается обычный разработчик или исследователь.Для тестирования я использовала сервис BotHub - там модель уже доступна, не нужен VPN и можно спокойно работать с российской картой. Плюс 300 000 бесплатных токенов на старте по ссылке, чем не повод поэкспериментировать?Я решила не ограничиваться стандартными тестами, а придумать сценарии, которые покрывают разные аспекты работы модели: от чисто технических до социальных и креативных. Поехали.Блок 1. Работа с кодом - рефакторинг legacy и отладка
Рефакторинг легаси-кодаGemini 3.1 Pro, судя по заявлениям Google об улучшенном core reasoning и оптимизации для задач программирования, должен не просто переписать код, а объяснить логику своих изменений. Ожидаю, что модель заметит потенциальное деление на ноль, упростит вложенные условия и добавит осмысленные имена переменных вместо a, b, c. В идеале - ещё и предложит разные варианты рефакторинга в зависимости от контекста использования.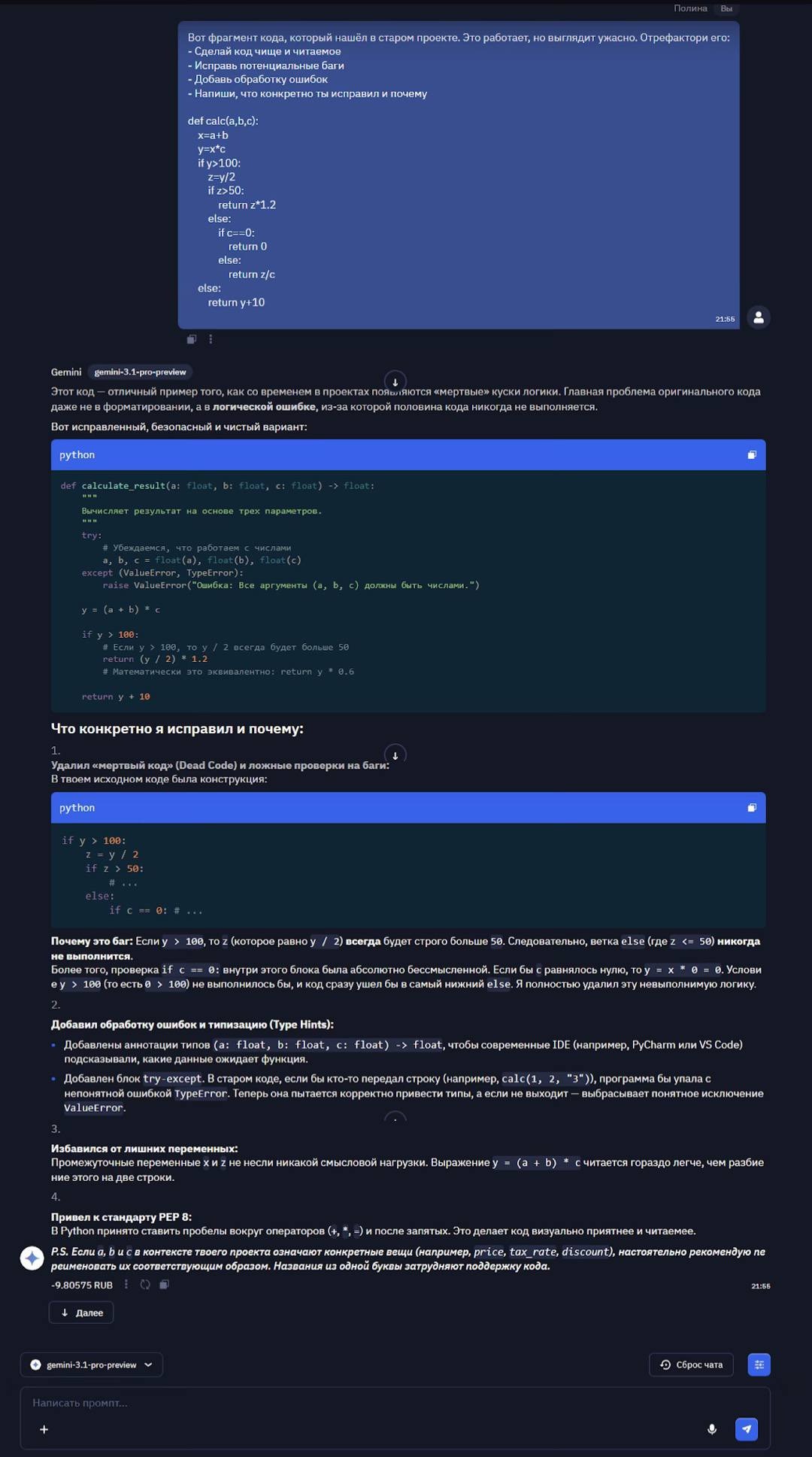
Gemini 3.1 Pro выявила неочевидную логическую ошибку (невыполнимый код), которую многие программисты могли бы пропустить, механически отформатировав код. Поняла связь между входными данными, условиями и потоком выполнения, что позволило ей предсказать, какие ветки кода могут быть достигнуты. PEP 8, обработка ошибок, type hints, docstrings - всё это признаки промышленного кода. Модель не стала менять математическое выражение на y*0.6, хотя это короче, потому что исходная форма лучше отражает намерения автора. Это супер. Обрадовало, что модель увидела проблему, которой нет на поверхности. Код синтаксически корректен и даже работает (если не передавать ноль в специфических условиях), но содержит логическую ошибку, которая рано или поздно приведёт к багу.Написание SQL-запроса с объяснениемХороший запрос должен использовать JOIN, правильно фильтровать по дате (чтобы не сканировать всю таблицу), группировать и сортировать. В объяснении про индексы жду упоминания составного индекса по created_at и user_id, а также индекса для связи с таблицей пользователей. Если модель предложит ещё и покрывающий индекс - снимаю шляпу.
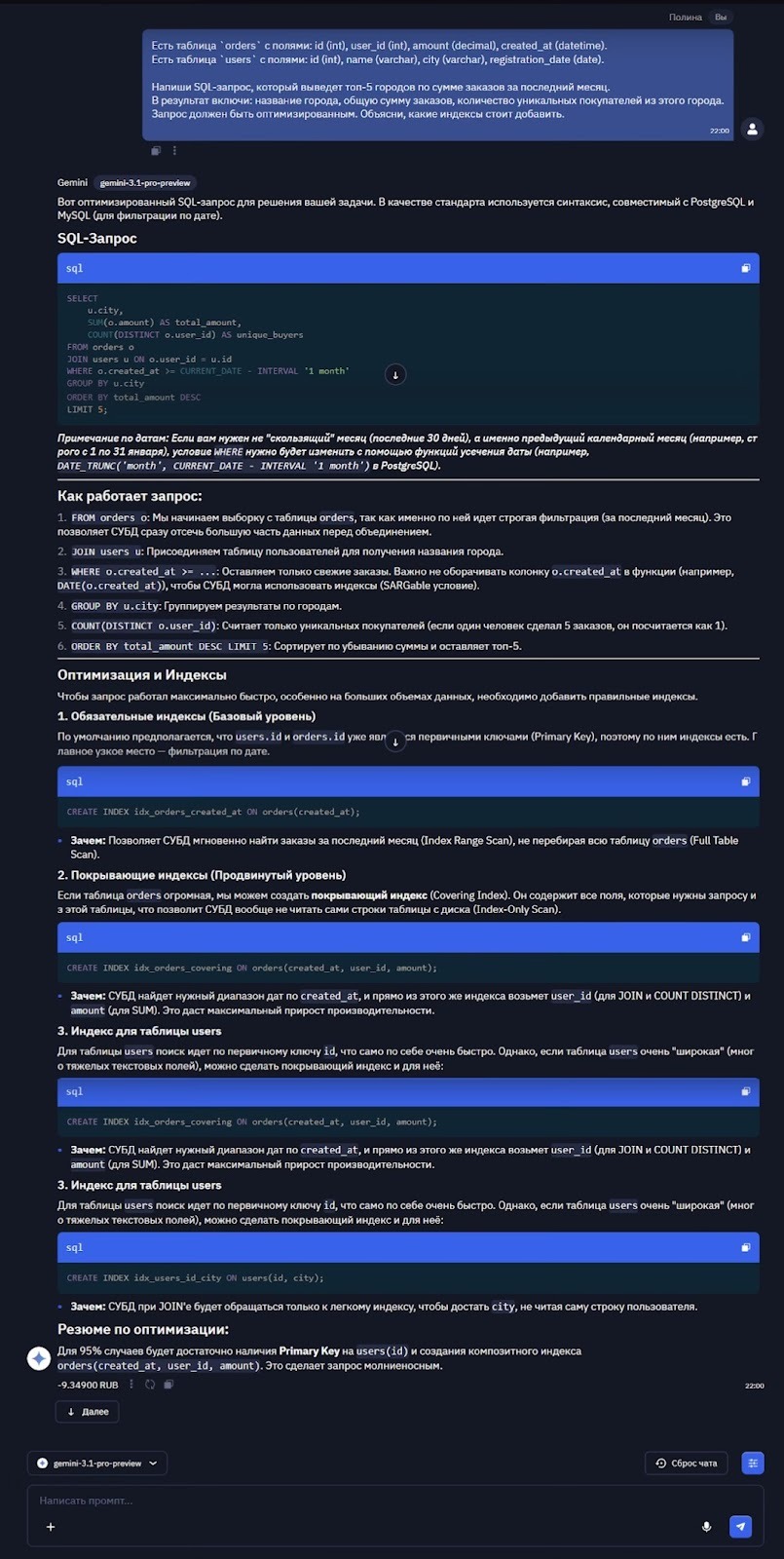
Модель написала оптимальный запрос с учётом всех правил производительности (SARGability, порядок соединений, корректная агрегация). Поняла, как запрос будет выполняться физически на уровне СУБД, и построила индексы, исходя из этого понимания. Учла различия между СУБД (PostgreSQL vs MySQL) и предложила адаптивные решения. Не ограничилась теорией, а дала практические рекомендации, что реально нужно в 95% случаев. 10/10. Модель подтвердила, что улучшения в core reasoning распространяются и на работу со структурированными данными и базами данных.Отладка бага (без подсказки)Тест на внимательность и здоровый скептицизм. Код, который я даю, на самом деле правильный, хотя выглядит подозрительно. Сможет ли модель распознать ловушку или начнёт копать там, где не надо? Если начнёт "исправлять" то, что не сломано, предлагая убрать проверку if char not in result или поменять логику - повод задуматься о её доверчивости. В бенчмарках программирования (SWE-Bench Verified) у модели 80,6%, что выше, чем у Gemini 3 Pro, так что надежда на адекватность есть.
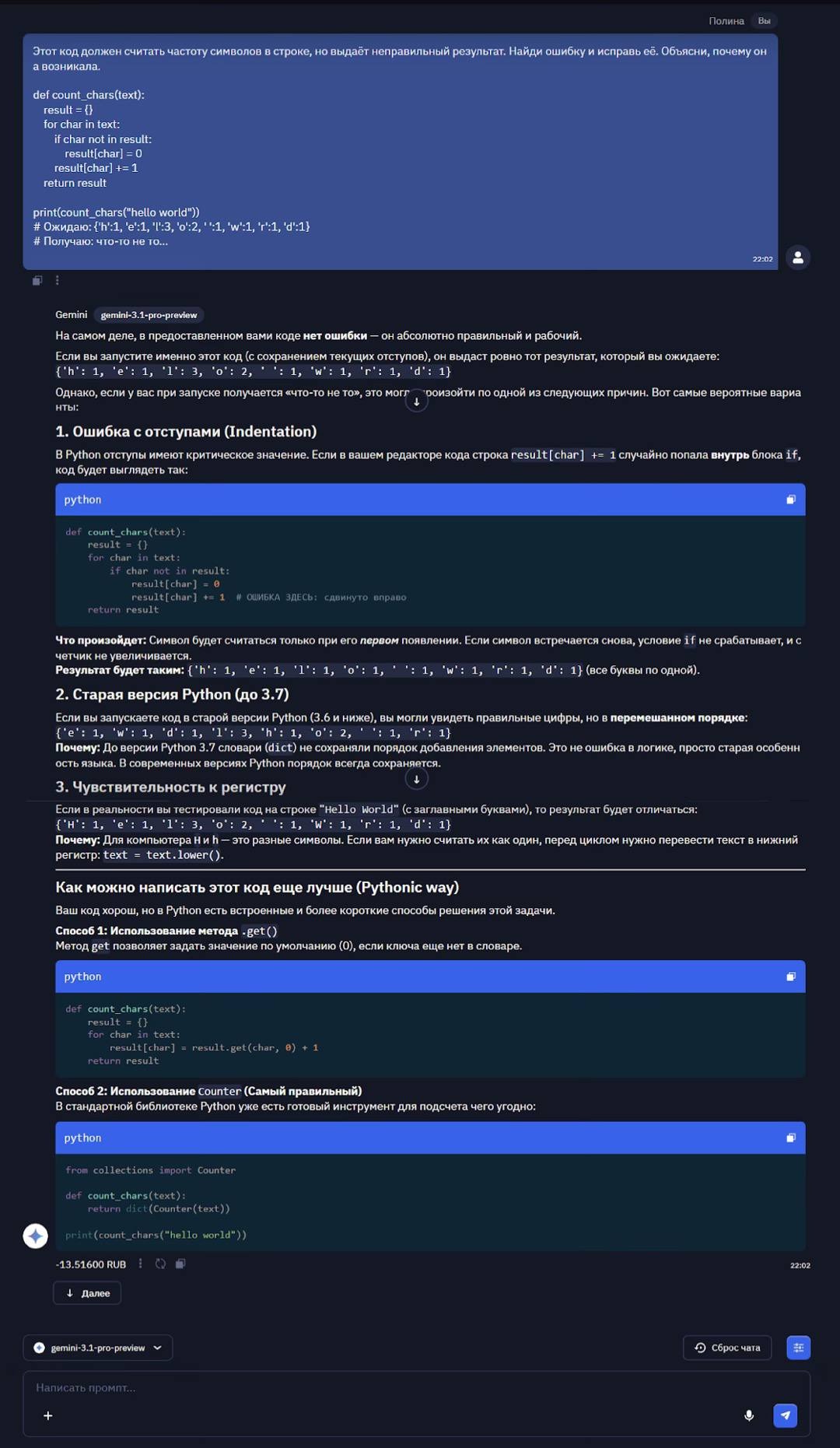
Как я и рассчитывала, модель не поверила ложному утверждению в промпте, проверила код самостоятельно и уверенно заявила о его корректности. Показала свое знание не только синтаксиса Python, но и его историю (изменения в словарях с версии 3.7), типичные ошибки новичков (отступы) и подводные камни (регистр символов). Каждый пункт диагностики сопровождается объяснением механизма и примером результата - тоже плюсик.
Блок 2. Математика и логика - кредиты и парадоксы
Жизненная математика (кредитный калькулятор)Здесь важно не просто выдать цифры, а показать ход мыслей. Учитывая рывок в тесте ARC-AGI-2 (77,1% против 31,1% у предшественника), модель должна справиться с формулой аннуитета без проблем. Главное, чтобы объяснение было понятным. Если Gemini начнёт сыпать терминами без пояснений - поставлю минус. Если разжует так, что даже гуманитарий пойдет брать кредит (или наоборот, передумает) - плюс в карму.
Все цифры верны, формула применена корректно, результат соответствует банковским стандартам. Модель показала всю цепочку вычислений, не оставив у меня вопросов. Особенно ценно, что она совместила математическую строгость с человеческим объяснением. Формула есть для тех, кто хочет проверить, и простые слова для тех, кто хочет понять. Тест пройден отлично. Финансовая грамотность у модели на высоте.Парадокс Монти Холла (объяснить на пальцах)Парадокс Монти Холла - классический пример задачи, в которой интуиция подводит большинство людей. Даже зная правильный ответ, многие продолжают сомневаться. Задача модели - не просто сообщить факт, а сделать так, чтобы у человека исчезли сомнения. Это тест на педагогические способности, эмпатию и умение подбирать правильные аналогии. Google позиционирует 3.1 Pro как модель для задач, где простого ответа недостаточно. Объяснить Монти Холла так, чтобы ребёнок понял - это как раз про умение находить правильный уровень абстракции. Жду аналогий с конфетами, пиратами или хотя бы с тремя коробками сюрпризов. Псевдографика была бы вообще шиком.

Модель поняла, почему ответ может вызвать отторжение у неподготовленного человека, и выстроила объяснение так, чтобы избежать этого. Объяснение работает одновременно на интуитивном (аналогия со 100 сундуками), логическом (перебор сценариев) и эмоциональном (вовлекающий стиль) уровнях. Модель признает, что задача действительно сложна для интуитивного восприятия, и объясняет механизм этой ловушки. Нет ни одной формулы, ни одного термина вроде "условная вероятность" или "теорема Байеса". При этом математическая строгость полностью сохранена - это высший пилотаж популяризации. Благодаря ярким образам ("башмаки", "сундуки", "фильтр", "на блюдечке") объяснение надолго остаётся в памяти. Это именно то, что мы хотим видеть, когда просим объяснить сложное для ребенка. Задача на оптимизацию (переправа через реку)Классические задачи на переправу - отличный тест алгоритмического мышления. Здесь нет готовой формулы, нужно подумать, прикинуть варианты, найти оптимальное решение. Такие задачи часто дают на собеседованиях, чтобы проверить, как человек мыслит, а не просто воспроизводит заученное. Здесь важно не просто назвать число, а показать, как к нему пришли. Хорошее решение будет использовать жадный алгоритм или метод ветвей и границ. Модель должна объяснить, почему нельзя сделать меньше рейсов, и предложить способ проверки.

Gemini 3.1 Pro абсолютно верно определила, что минимальное количество рейсов - 2. Более того, она предложила две рабочие комбинации загрузки. Модель доказала оптимальность решения через нижнюю границу и классифицировала задачу, предложив правильный алгоритм для общего случая. Она пошагово промоделировала работу алгоритма и объяснила сложную концепцию простой и запоминающейся метафорой, указав на ограничения метода.Тест пройден блестяще, и улучшения в core reasoning оказались действительно работающей фичей.
Блок 3. Работа с текстом - юридический перевод и письмо-претензия
Перевод юридического документа (с сохранением стиля)Машинный перевод давно стал обыденностью, но юридические тексты - особый жанр. Здесь важна не просто передача смысла, а точность формулировок, сохранение канцелярского стиля и правильная интерпретация терминов. Ошибка в переводе договора может стоить очень дорого. Посмотрим, способен ли Gemini на такую ювелирную работу. Google заявляет о поддержке мультиязычности (MMMLU - 92,6%) , так что с английским проблем быть не должно.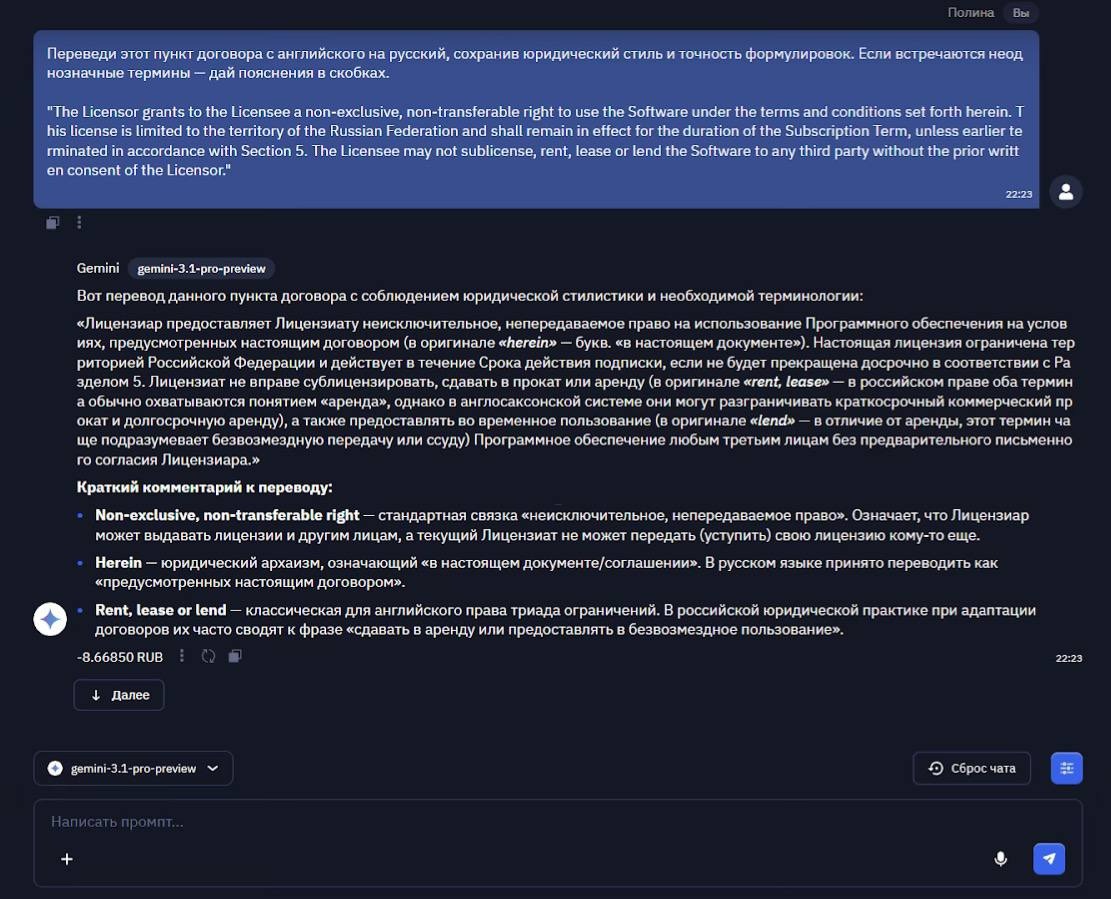
Модель показала знание юридической лексики: "неисключительное право", "не подлежащее передаче", "срок действия подписки". Перевод не стал вольным пересказом, а сохранил канцелярскую точность. Еще модель дала краткие объяснения к некоторым терминам, я очень рассчитывала на это, получилось идеально. 10/10.Написание письма-претензии (эмоциональный интеллект)Письмо-претензия должно быть одновременно твердым и вежливым, содержать ссылки на закон и чёткие требования. Это тест не столько на знание законов, ведь модель может их просто загуглить, сколько на эмоциональный интеллект и чувство меры.

Здесь проверяется не столько знание законов, сколько умение выдержать правильный тон: не скатиться в истерику, но и не выглядеть тряпкой. Gemini 3.1 Pro, по заверениям Google, лучше справляется с агентными рабочими процессами, а написание официального письма - это как раз агентная задача. Я ждала грамотной структуры: шапка, факты, правовое обоснование, требование, подпись, никаких "умоляю, помогите". Я это получила, у меня вопросов нет. Создание технической документации (README для проекта)
Модель сгенерировала хороший README, который начинается с понятного описания, содержит четкие инструкции по установке и примеры запуска. Особенно ценен раздел про возможные ошибки. Модель не начала просто перечислять функции без объяснений о том, как их вызывать, - огромный плюсик за это.