Llama
2 février 2025
Опенсорс на арене: правда ли так хороша Llama 3.1 405B?
В 2024 году Meta* представила миру Llama 3.1 405B - новую открытую модель, бросающую вызов признанным лидерам, таким как GPT-4o и Claude-3.5 Sonnet.15 триллионов токенов, 16 000 графических процессоров H100, улучшенные возможности рассуждений и генерации кода - впечатляющие характеристики. Но действительно ли Llama 3.1 способна состязаться с закрытыми моделями? В этой статье мы проведем независимое расследование: сравним возможности Llama 3.1 405B с GPT-4o и Claude 3.5 Sonnet на ряду задач, от программирования до творческого письма, и попробуем понять, насколько она готова к практическому применению.

Что за модель?
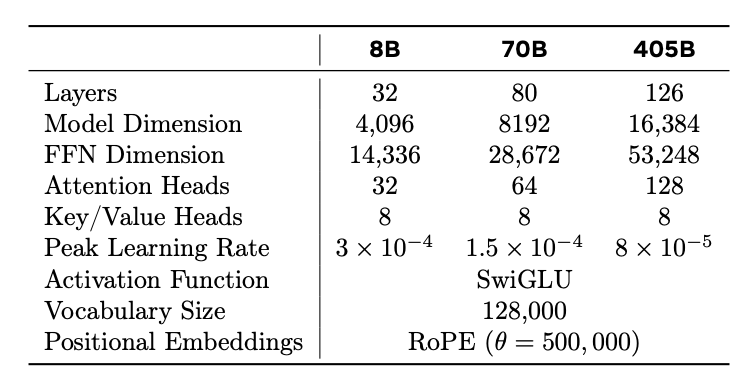
Llama 3.1 405B - это самая большая модель от Meta*, обученная на колоссальном объеме данных – более 15 триллионов токенов. Для обучения модели такого масштаба Meta пришлось не только задействовать огромные вычислительные мощности – более 16 000 графических процессоров NVIDIA H100, – но и оптимизировать сам процесс обучения.По заявлениям Meta, Llama 3.1 405B значительно превосходит предыдущие версии (Llama 1 и Llama 2) по таким параметрам, как длина контекстного окна (теперь она составляет 128 тысяч токенов), способность к логическим рассуждениям и написанию программного кода.Помимо версии с 405 млрд параметров, доступны также модели поменьше - с 8 млрд и 70 млрд параметров. Подробнее о характеристиках всех трех версий можно узнать из таблицы ниже.
В дополнение к основным моделям, Meta также представила Llama-Guard-3–8B — специальную версию 8-миллиардной модели, настроенную на классификацию данных на основе контента. Также все модели Llama 3.1 "понимают" восемь языков: английский, немецкий, французский, итальянский, португальский, хинди, испанский и тайский.Обучение Llama 3.1 проходило в два этапа. Сначала, на этапе предварительного обучения, модель "впитывала" информацию из огромного текстового массива (более 15 триллионов токенов), обрабатывая его на мощном кластере графических процессоров. Затем, на этапе пост-обучения, происходила более тонкая настройка, где использовались методы контролируемого обучения (SFT), выборки с отклонением и прямой оптимизации предпочтений (DPO).Стоит отметить, что для повышения эффективности модели в задачах программирования, математических вычислений и использования инструментов на этапе SFT применялись специально подготовленные высококачественные синтетические данные. Более подробно об этом процессе можно узнать из пункта 4.2.3 документации.
Meta* утверждает, что Llama 3 демонстрирует впечатляющие способности к программированию: она генерирует качественный код, демонстрируя глубокое понимание синтаксиса и логики программирования. Модель способна не только создавать сложные структуры, но и успешно справляться с разнообразными задачами. Кроме того, Llama 3 блестяще проявляет себя в задачах, требующих логического мышления: она умеет рассуждать, анализировать, делать выводы и находить решения даже для нетривиальных задач.
Бенчмарки
Llama 3.1 прошла тщательное тестирование: её возможности были оценены как на основе более чем 50 наборов данных, так и с привлечением экспертов. Результаты экспериментов показали, что модель демонстрирует производительность на уровне таких признанных лидеров, как GPT-4, GPT-4o и Claude 3.5 Sonnet. Отдельно стоит отметить способность Llama 3.1 эффективно работать с длинными текстами – в тесте "zero scrolls quality" она получила впечатляющие 95,2 балла.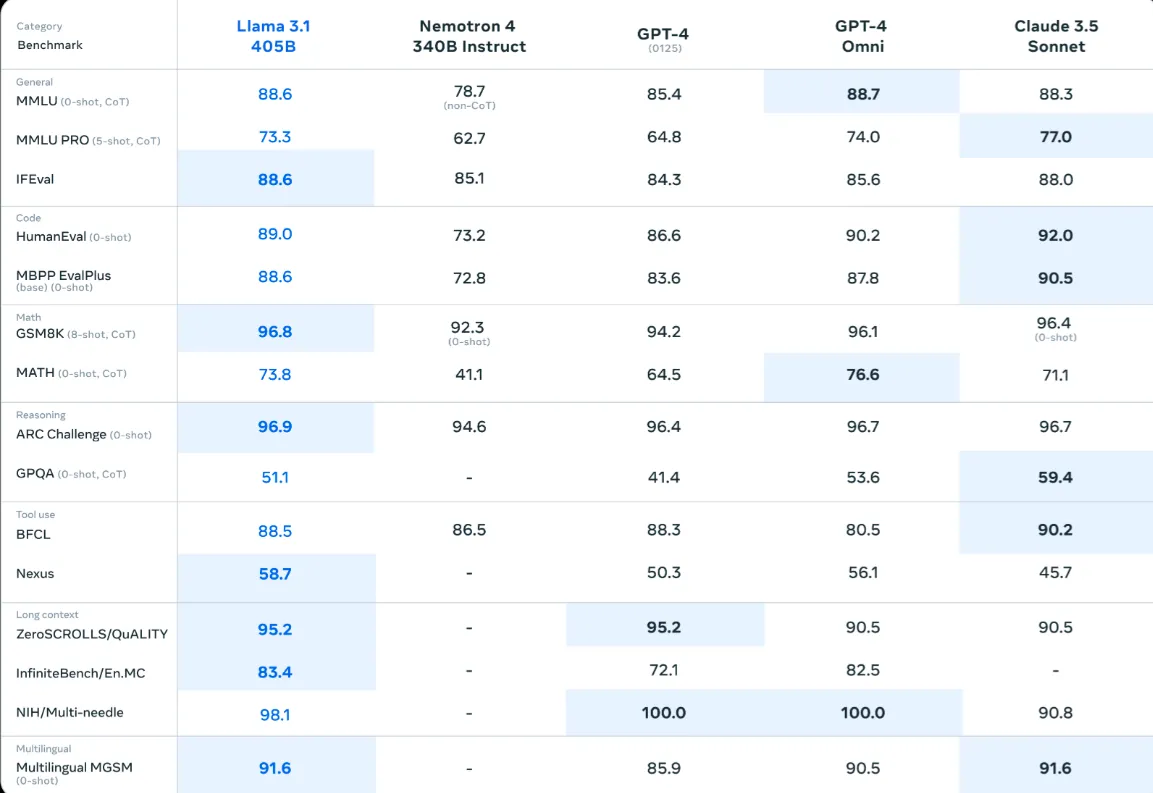
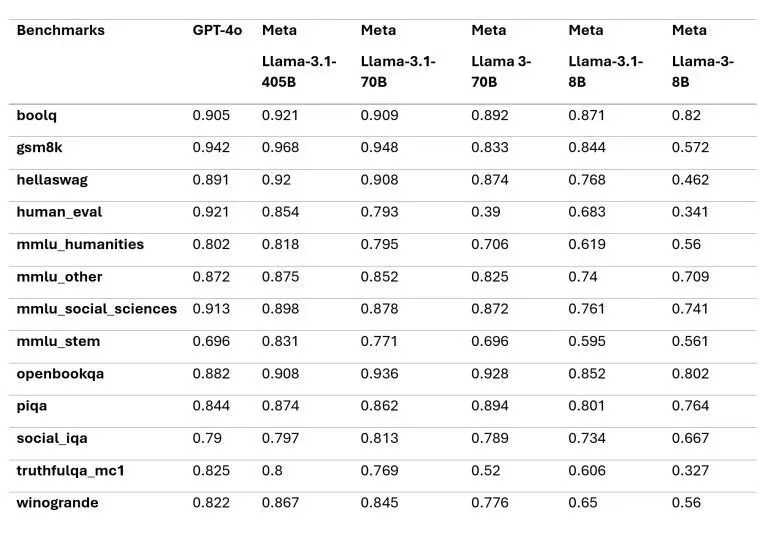
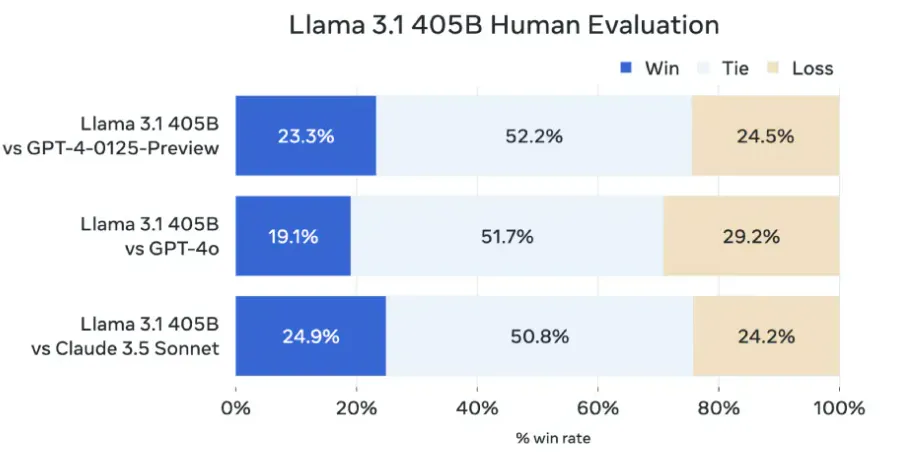
Llama 3.1 продемонстрировала превосходство над GPT-4o в ряде тестов, таких как GSM8K, Hellaswag, boolq, MMLU-humanities, MMLU-other, MMLU-stem и winograd. Однако в некоторых дисциплинах, например, в тестах HumanEval и MMLU-social sciences, GPT-4o оказалась сильнее. Также стоит отметить, что Claude 3.5 Sonnet превзошла Llama 3.1 в тестах BFCL и Nexus.Ручная оценка экспертов показала, что в целом производительность Llama 3.1 405B сопоставима с GPT-4 и Claude 3.5 Sonnet, хотя и немного уступает GPT-4o.
Генерация кода
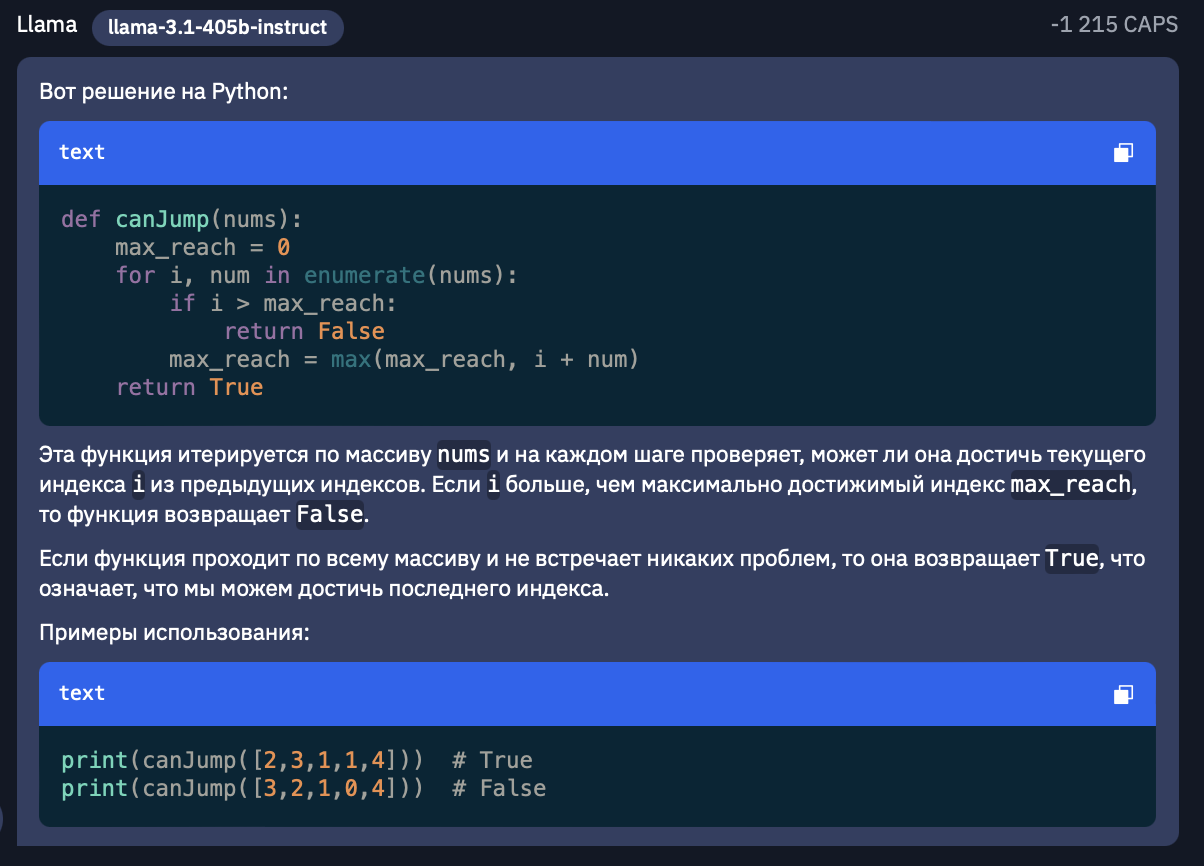
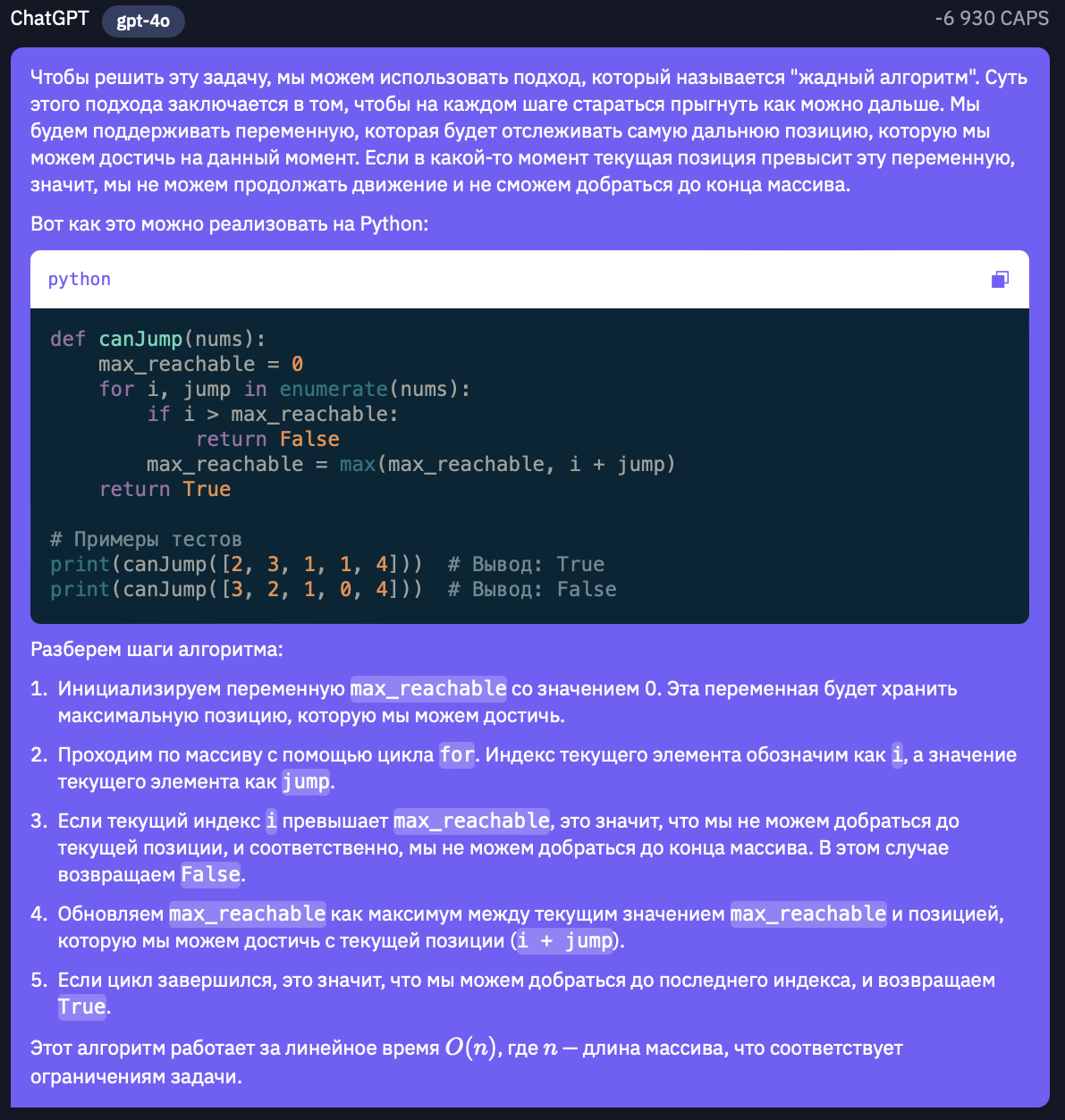
Возьмем 55-ю задачу на динамическое программирование с LeetCode. Да, сразу отмечу, промты буду писать на русском, поскольку нам интереснее сравнить как модели работают именно с русским языком.Итак, наш промт:Дан массив целых чисел nums. Изначально вы находитесь в первом элементе массива, и каждый элемент массива представляет максимальную длину прыжка с этой позиции.Верните true, если вы можете добраться до последнего индекса, и false в противном случае.Пример 1:Вход: nums = [2,3,1,1,4] Выход: true Объяснение: Сделайте 1 шаг с индекса 0 на 1, затем 3 шага до последнего индекса.Пример 2:Вход: nums = [3,2,1,0,4] Выход: false Объяснение: Вы всегда будете попадать на индекс 3, несмотря ни на что. Его максимальная длина прыжка равна 0, что делает невозможным достижение последнего индекса.Ограничения:1 <= nums.length <= 10^4 0 <= nums[i] <= 10^5
Llama 3.1 405B
ChatGPT-4o
Claude-3.5 Sonnet
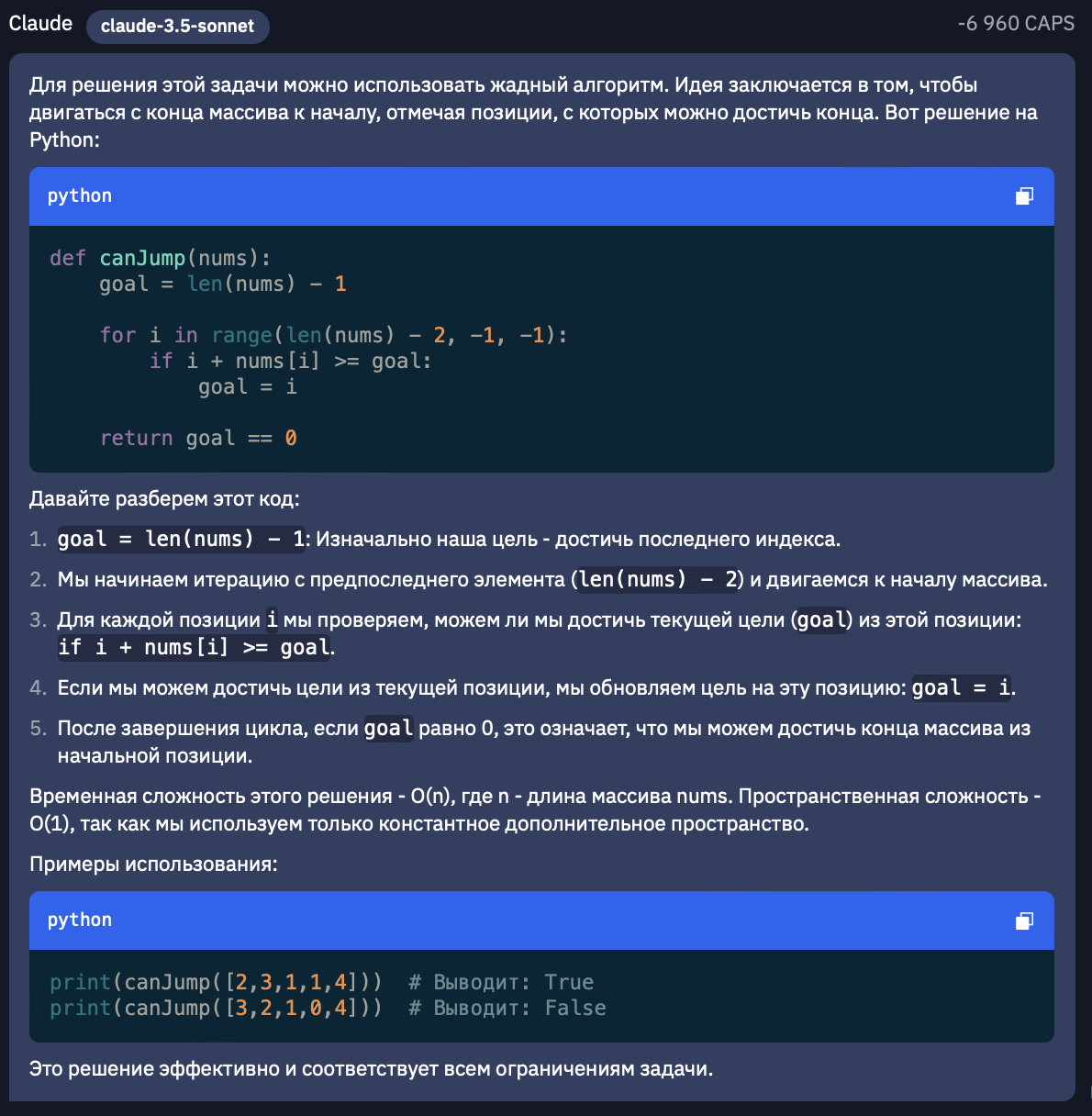
Итак, первое, что бросается в глаза - ответ Llama наименее подробный. Описание самого алгоритма поверхностное в сравнении с Gpt-4o, однако все-таки объясняет почему этот алгоритм работает. А если говорить про код, то Sonnet представил более лаконичный код в сравнении с Llama. Двигаемся дальше.
Математика
Далее возьмем несложную математическую задачу, которая требует внимательности к формулировке. Наш промт будет выглядеть следующим образом:Кирпич весит 1 кг и полкирпича. Сколько весит кирпич?
Llama 3.1 405B

ChatGPT-4o

Claude-3.5 Sonnet

Итак, ответы моделей перед глазами. Первое - каждая ответила правильно, однако все-таки по разному. Ответ Llama можно охарактеризовать понятностью, доступностью и легкой неформальностью. Например, в сравнении с Sonnet детализация гораздо меньше, а в сравнении с GPT - избегает уравнений. Плюсы это или минусы - зависит от цели и аудитории.Предлагаем дать еще одну задачу:
Автобус едет со скоростью 56 миль в час. В последнем ряду сидят три человека, а в предпоследнем - два. Сколько всего людей в автобусе?
Llama 3.1 405B

ChatGPT-4o

Claude-3.5 Sonnet

Генерация текста
И замкнет наше сравнение генерация творческого текста, например, попросим необычный рецепт обычного борща(базово):Напиши рецепт борща, но так, как будто это инструкция по сборке космического корабля
Llama 3.1 405B

ChatGPT-4o

Claude-3.5 Sonnet

Все три модели, конечно, хорошо справились с задачей и переосмыслили рецепт борща в стиле инструкции по сборке космического корабля. Llama здесь выделяется именно балансом, одна модель больше уходит в атмосферу, другая в структуру, а Llama предлагает нечто среднее.Llama 3.1 405B - вполне конкурентоспособная LLM, демонстрирующая высокие результаты во многих задачах. Она успешно справляется с генерацией кода, решением логических задач и творческим текстом. Однако прямое сравнение с GPT-4o и Claude 3.5 Sonnet на русском выявляет и некоторые слабые стороны, например, в детализации объяснений или лаконичности кода. Тем не менее, не стоит забывать, что Llama 3.1 - это опенсорсная модель, а значит, она имеет огромный потенциал для дальнейшего развития и улучшения. Открытый исходный код позволит исследователям и разработчикам со всего мира вносить свой вклад в ее совершенствование, что в перспективе может привести к созданию еще более мощных и доступных инструментов на базе ИИ.*Организация Meta признана экстремистской, её деятельность запрещена на территории РФ