ChatGPT
3 февраля 2025 г.
OpenAI о новых LLM, которые умеют рассуждать
Модели OpenAI серии o1 — это новые большие языковые модели, обученные с помощью подкрепления для выполнения сложных рассуждений. Модели o1 думают, прежде чем ответить, и могут создавать длинную внутреннюю цепочку рассуждений, прежде чем ответить пользователю.Модели o1 отлично справляются с научными рассуждениями, занимая 89-е место в процентах при решении конкурсных вопросов по программированию (Codeforces), входя в число 500 лучших студентов США в отборочном туре математической олимпиады США (AIME) и превышая точность человека на уровне доктора наук при решении задач по физике, биологии и химии (GPQA).
В API доступны две модели, умеющие рассуждать:
- o1-preview: ранняя предварительная версия нашей модели o1, разработанная для рассуждений о сложных проблемах с использованием общих знаний о мире.
- o1-mini: более быстрая и дешевая версия o1, особенно эффективная в задачах, связанных с программированием, математикой и науками, где не требуются обширные общие знания.
Быстрый запуск
И o1-preview, и o1-mini доступны через chat completions endpoint."from openai import OpenAI client = OpenAI() response = client.chat.completions.create( model="o1-preview", messages=[ { "role": "user", "content": "Write a bash script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format." } ] ) print(response.choices[0].message.content)"
В зависимости от объема рассуждений, необходимых модели для решения проблемы, эти запросы могут занимать от нескольких секунд до нескольких минут.
Как работают рассуждения
В моделях o1 представлены токены для рассуждений. Модели используют их, чтобы «думать», разбивая свое понимание подсказки и рассматривая несколько подходов к формулирования ответа. После генерирования токенов рассуждений модель выдает ответ в виде видимых токенов завершения и выбрасывает токены рассуждений из своего контекста.Вот пример многоэтапного общения между пользователем и помощником. Входные и выходные токены с каждого шага переносятся, а токены рассуждений сбрасываются.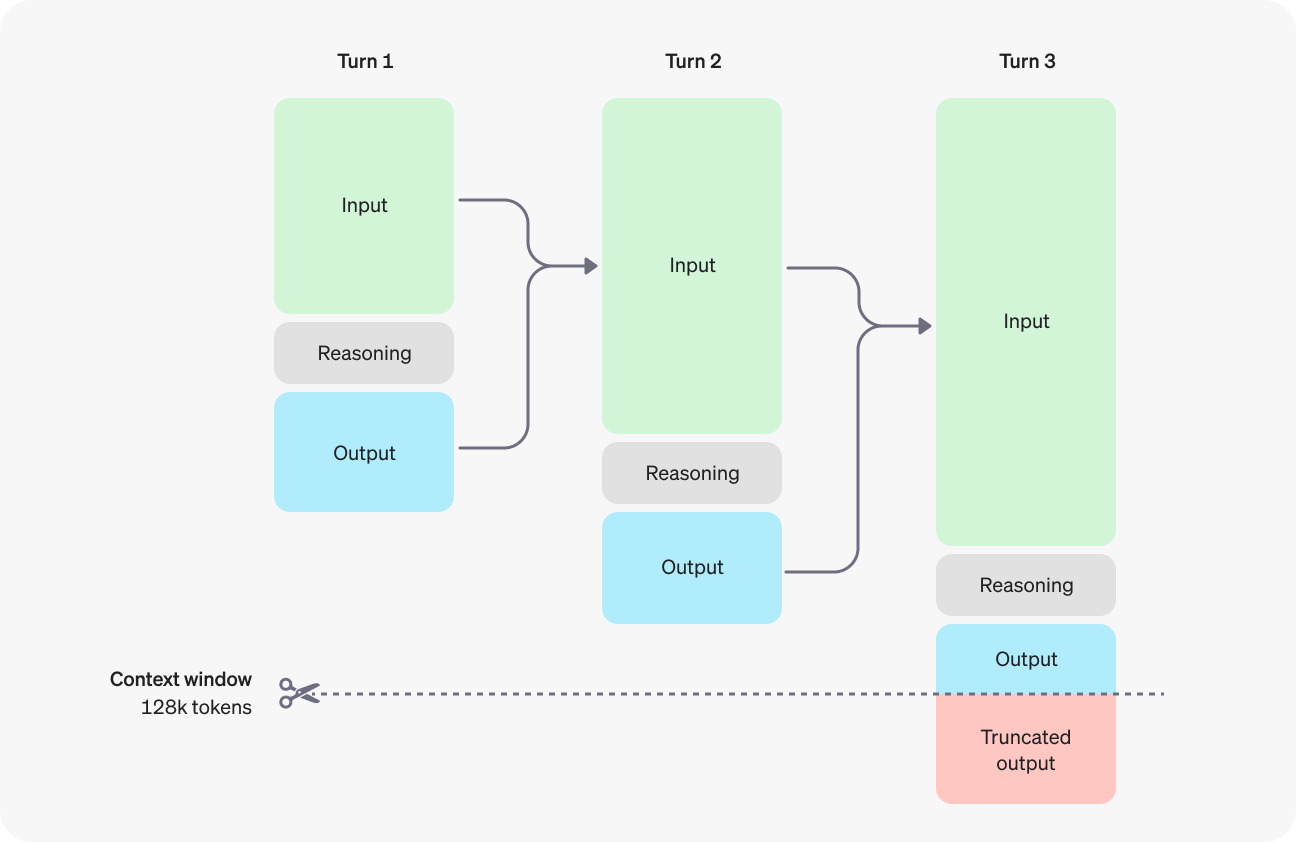
Хотя токены рассуждений не видны через API, они все равно занимают место в контекстном окне модели и называются токенами вывода.
"usage: { total_tokens: 1000, prompt_tokens: 400, completion_tokens: 600, completion_tokens_details: { reasoning_tokens: 500 } }"
Управление контекстным окном
Модели o1-preview и o1-mini предлагают контекстное окно из 128 000 токенов. Каждый completion имеет верхнее ограничение на максимальное количество выводимых токенов — сюда входят как невидимые токены рассуждений, так и видимые токены завершения. Максимальные ограничения на количество выводимых токенов следующие:o1-preview: до 32 768 токенов
o1-mini: до 65 536 токенов
"usage: { total_tokens: 1000, prompt_tokens: 400, completion_tokens: 600, completion_tokens_details: { reasoning_tokens: 500 } }"
Контроль затрат
Чтобы управлять затратами в моделях серии o1, вы можете ограничить общее количество генерируемых моделью токенов (включая токены рассуждения и завершения) с помощью параметра max_completion_tokens.В предыдущих моделях параметр max_tokens контролировал как количество генерируемых токенов, так и количество токенов, видимых пользователю, которые всегда были равны. Однако в серии o1 общее количество сгенерированных токенов может превышать количество видимых токенов из-за внутренних токенов рассуждений.Поскольку некоторые приложения могут полагаться на соответствие max_tokens количеству токенов, полученных от API, в серии o1 введено max_completion_tokens для явного контроля общего количества токенов, генерируемых моделью, включая как токены рассуждений, так и видимые токены завершения. Этот явный выбор гарантирует, что существующие приложения не будут ломаться при использовании новых моделей. Параметр max_tokens продолжает работать как и раньше для всех предыдущих моделей.Выделения пространства для рассуждений
Если количество сгенерированных токенов достигнет предела контекстного окна или заданного вами значения max_completion_tokens, вы получите ответ о завершении работы в чате с параметром finish_reason, установленным на длину. Это может произойти до того, как будут созданы видимые токены завершения, что означает, что вы можете понести затраты на ввод и аргументацию, не получив видимого ответа.Чтобы предотвратить это, убедитесь, что в контекстном окне достаточно места, или измените значение max_completion_tokens на более высокое. OpenAI рекомендует зарезервировать не менее 25 000 токенов для рассуждений и выводов, когда вы начинаете экспериментировать с этими моделями. По мере того как вы будете знакомиться с количеством токенов для рассуждений, требуемых вашими промптами, вы сможете соответствующим образом регулировать этот буфер.Советы по промптингу
Эти модели лучше всего работают с прямыми промптами. Некоторые методы разработки промптов, например, промпты из нескольких кадров или указания модели «думать шаг за шагом», не только не повышают эффективность работы, но и иногда мешают ей. Вот несколько лучших практик:- Сохраняйте простоту и прямоту подсказок: модели прекрасно понимают и реагируют на краткие и четкие инструкции, не требующие подробных указаний.
- Избегайте промптов в виде цепочки мыслей: поскольку эти модели проводят рассуждения внутри себя, побуждать их «думать шаг за шагом» или «объяснять свои рассуждения» не нужно.
- Используйте разделители для ясности: используйте разделители, такие как тройные кавычки, XML-теги или названия разделов, чтобы четко обозначить отдельные части входных данных, помогая модели правильно интерпретировать различные разделы.
- Ограничьте дополнительный контекст в генерации с расширенным поиском (RAG): предоставляя дополнительный контекст или документы, включайте только самую важную информацию, чтобы модель не усложняла свой ответ.
Примеры промптов
Программирование (рефакторинг)
Программирование (planning)
STEM Research