ChatGPT
Claude
9 декабря 2025 г.
GPT-5 vs Claude Opus 4.5 vs Gemini 3 Pro: битва reasoning-моделей. Кто победил в 2025?
Год близится к завершению, и за это время мы получили в распоряжение множество вполне достойных моделей. Взять хотя бы тот факт, что в ближайшее время ожидается выход новой версии GPT. К тому же, после моей предыдущей статьи о Claude Opus 4.5 родилась идея: почему бы не устроить состязание среди лидирующих сейчас текстовых моделей?Сегодня в битве участвуют: GPT-5, Claude Opus 4.5 и Gemini 3 Pro. Делайте ставки, а мы приступаем к сравнению.

Краткий экскурс
Claude Opus 4.5
Самая мощная модель от Anthropic, уже признанная лидером в сфере программирования. Если нужно решить действительно сложную задачу, написать код или разобраться в запутанной теме - это работа для Claude Opus 4.5.Модель, как сказано выше, демонстрирует великолепные навыки в написании кода, обладает продвинутыми мультимодальными возможностями (отлично работает с визуализацией) и поддерживает длинный контекст (эффективна в продолжительных диалогах).GPT-5
Масштабная языковая модель от OpenAI, сочетающая инженерную устойчивость, многофункциональность и управляемость.В отличие от предыдущих релизов компании, GPT-5 - не одна модель, а интегрированная система с динамической маршрутизацией, многоуровневой безопасностью и адаптацией под конкретные задачи. Она разрабатывалась не для повышения результатов в бенчмарках, а для решения практических задач бизнеса, науки, программирования и здравоохранения. Нельзя также забыть о качестве рассуждений и стабильности.Кстати, уже скоро - состоится релиз GPT-5.2. Ответ OpenAI на выход Claude Opus 4.5 от Anthropic.Gemini 3 Pro
Gemini 3 Pro - это флагманская LLM от Google, новейшее поколение, объединяющее все возможности поколений 1, 2 и 2.5. Google называет ее самым интеллектуальным и фактологически точным искусственным интеллектом на сегодняшний день. Компания активно продвигает эту модель как новый этап эволюции.DeepMind характеризует Gemini 3 Pro как значительно превосходящую своего предшественника практически по всем параметрам, доступным для измерения: способность рассуждать, писать код, поддерживать мультимодальные взаимодействия и даже убедительно вести диалоги, демонстрируя убедительность даже в тех случаях, когда это требуется.Правила битвы
Все три модели пройдут через четыре задачи. В качестве оценки будет три вариации:- Плохо (1 балл)
- Хорошо (2 балла)
- Отлично (3 балла)
Первое задание
Первое задание будет, пожалуй, самым простым. Мне захотелось почитать творения ИИ и посмотреть, получится ли у них создать что-то адекватное в комедийном жанре. Собственно, задание и связано с этим.Напиши комедийный рассказ в жанре научной фантастики, состоящий из пяти объемных глав. Действие происходит в далеком будущем в галактической человеческой цивилизации.Основные требования:Сюжет: История обычного человека (например, техника, курьера, бюрократа), который по нелепой случайности попадает в центр межгалактического конфликта или абсурдной авантюры. Ключ - комедийные недоразумения и попытки выпутаться, которые лишь усугубляют ситуацию.Юмор: Основан на контрасте высоких технологий и низменных человеческих слабостей, сатире на современность, нелепых диалогах и гиперболе.Мир: Яркий, но не перегруженный деталями. Технологии должны быть на грани поломки, а грандиозные космические явления - вызывать бытовые неудобства.Структура: Пять глав с четкой драматургией: Завязка - Развитие - Кризис - Решение - Развязка. В каждой главе должна быть своя комедийная кульминация.Финал: Должен быть удовлетворительным, подводить итоги трансформации героя и оставлять легкое, ироничное послевкусие.Второе задание
Здесь задание будет немного сложнее. И мы перейдем от литературы к математике. Вроде бы чего-то сложного тут нет, но слышал, что задача в конечном итоге оказывается достаточно трудной для моделей.Определи ранги элементов системы, заданной графом G = (V,U), где V – множество вершин, а U – множество реберV = {1,2,3,4,5} U= {(1,2)},(1,3),(1,4),(2,3),(2,4),(3,5),(4,5),(5,2)}.Сначала тебе нужно построить матрицу смежности a__ij.Затем тебе нужно построить матрицу полных путей p__ij.Ранг элемента равен R__i = \frac{\sum__{j} p__ij}{\sum__{ji} p__ij}Третье задание
Здесь я воспользуюсь идеей от одного из комментаторов прошлой статьи. Я немного доработал и усложнил ее.Привет! Ты - профессиональный разработчик игр. Напиши проект игры, суть которой:Полноценная игра в жанре RPG. В стартовом меню игрок может выбрать одну из трех рас (человек, эльф, дворф), а затем - один из пяти классов (воин, маг, друид, паладин, некромант). Должна быть реализована прокачка уровня с повышением характеристик, различные игровые активности и события (поход на миссию, защита королевства, поиск артефактов и тому подобное). Не забудь о GUI-интерфейсе. Язык программирования - Python.Четвертое задание
Финальным тестом станет несложная логическая задача, с которой модели часто справляются плохо.Автобус едет со скоростью 56 миль в час. В последнем ряду сидят три человека, а в предпоследнем - два. Сколько всего людей в автобусе?Такое задание мы уже встречали, поэтому сразу поясню: в моей трактовке водитель - не автопилот. Грубо говоря, модель должна понять, что в автобусе не менее шести человек.Задание первое
GPT-5
Первой на поле боя выйдет модель от OpenAI.
Не судите строго, но выше средней оценки я бы не поставил. Модель справилась с задачей, справилась достаточно быстро, но вот качество комедии, а для меня по большей части именно оно является определяющим фактором в этом задании, здесь хромает. Юмор тут не настолько смешной, зато в текст его заливают буквально ведрами. Словно лучше было бы меньше, но более забавных шуток, чем такое количество, которое лишь портит общее впечатление.
Claude Opus 4.5
Вообще, модель лидирует в кодинге, но и здесь способна продемонстрировать успех.
Результат от Claude значительно превосходит GPT-5, пожалуй, мой вердикт - максимальная оценка. Комедийная составляющая есть, пусть и не гениальная, но общее качество текста мне понравилось.
Gemini 3 Pro

С одной стороны, объем текста у Gemini меньше, чем у того же GPT, но я снова поставлю высший балл. Лично мне из трех рассказов больше всего понравился именно этот.
Задание второе
GPT-5

Задача решена неверно. Ранжирование - слабое место для многих моделей. Для тех, кому интересно, правильный ответ:R1 = 0.5;R2 = 0.154;R3 = 0.115;R4 = 0.115;R5 = 0.115;
Claude Opus 4.5

Ответ снова неверный, хотя я ожидал, что Claude справится с этой задачей.
Gemini 3 Pro

У меня было предчувствие, что все модели запутаются в этой задаче, - так и произошло. Gemini тоже провалился в задаче на ранжирование.
Третье задание
Пожалуй, здесь я не буду приводить скриншоты кода. Ощущаю, что их объем окажется слишком большим для статьи. Эх, уже представляю себе эти тридцать минут чтения по подсчетам Хабра.GPT-5
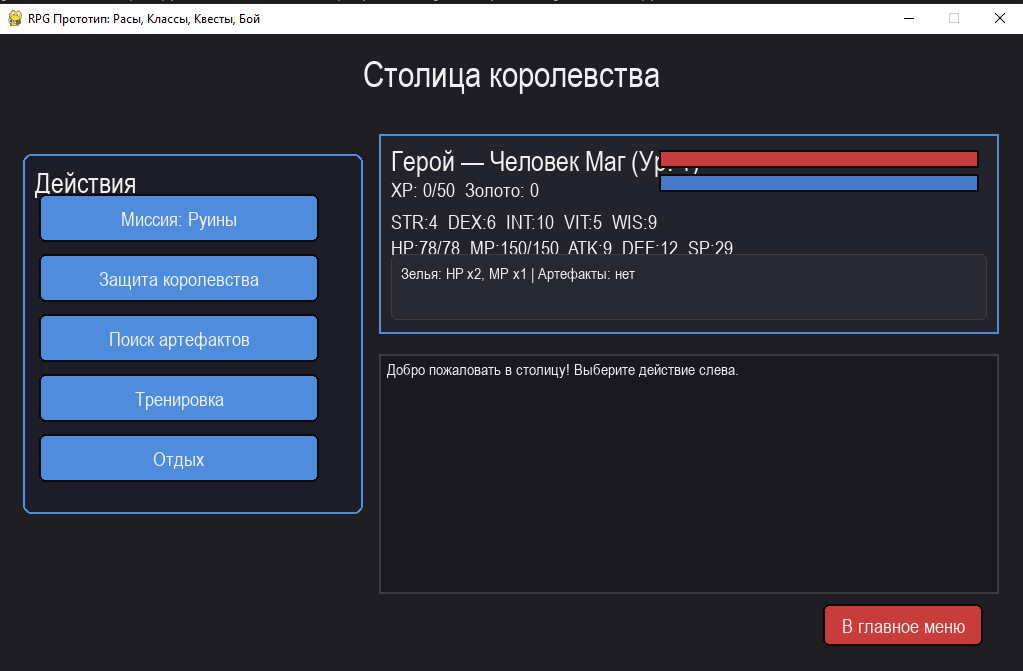
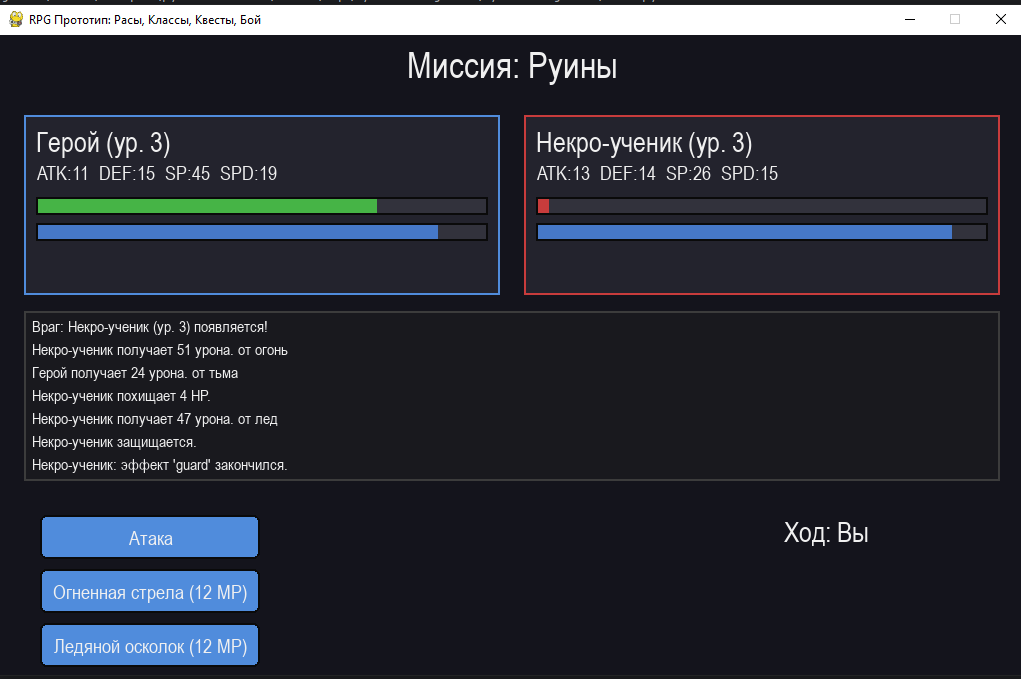
1200 строк кода, игра работает - топорно, но работает. Ничего особенного в реализации я не нашел. Из косяков - элементы худа наползают друг на друга, из-за чего порой трудно угадать, какой у тебя уровень. Класс волшебника - имба, сидишь, закидываешь врагов заклинаниями и становишься практически непобедимым.Это неплохая основа, хотя до полноценной игры ей еще далеко.
Claude Opus 4.5

2300 строк кода - на этом и закончили... Ошибка в функции, но ничего страшного, просьба поправить - и уже со второго захода удалось создать персонажа.
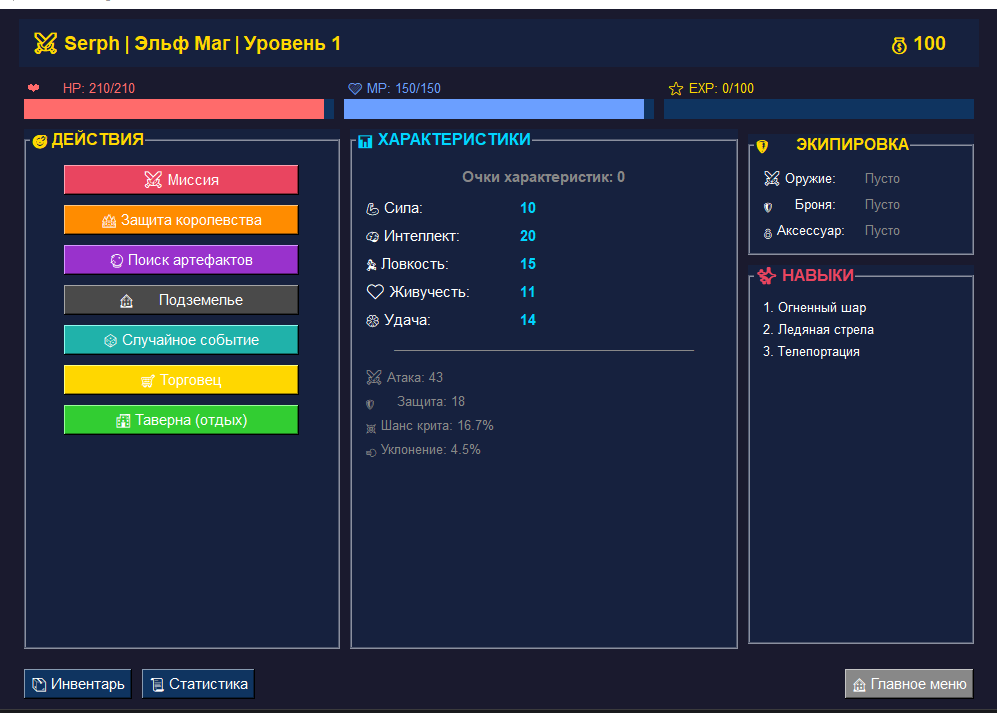
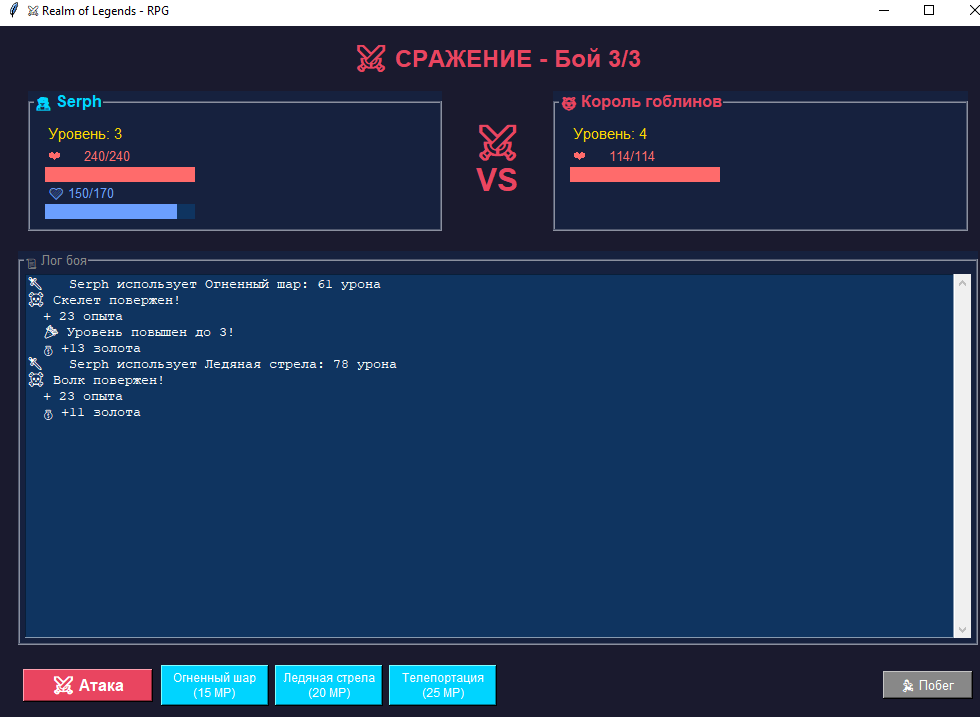
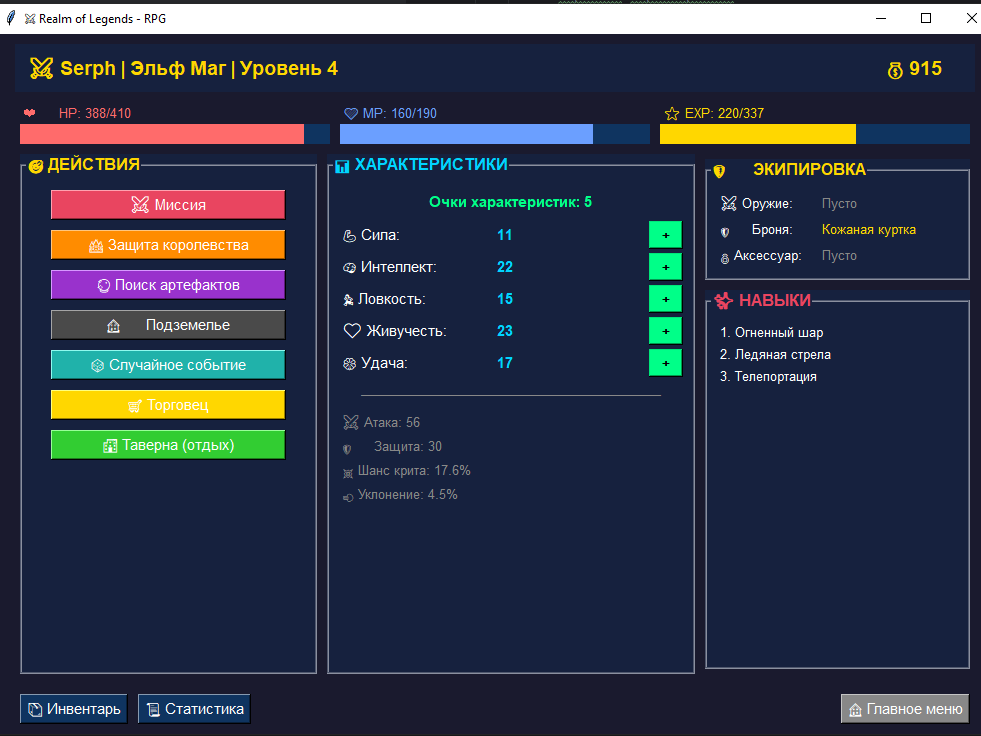
Здесь больше событий, лучше проработана игровая механика. Реализованы система прокачки характеристик, инвентарь, торговцы. В целом мне понравилось, следовательно, оценка очевидна. Конечно, было немного грустно увидеть ошибку при первой попытке - подумал, все, не получится поиграть, но нет, Opus 4.5 исправил все.
Gemini 3 Pro

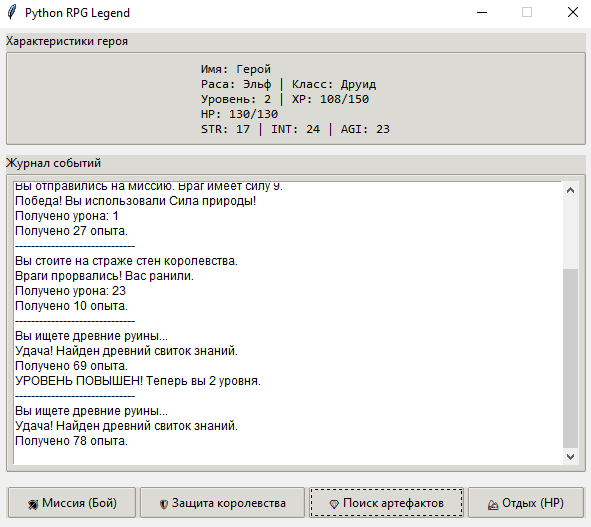
Результат явно нельзя назвать удовлетворительным, поэтому за это задание модель получает один балл. Ведь можно было сделать хотя бы на уровне GPT-5.
Четвертое задание
Задание на самом деле максимально простое, но оно направлено на логику. Интересно посмотреть, как модели определят количество человек в автобусе.GPT-5
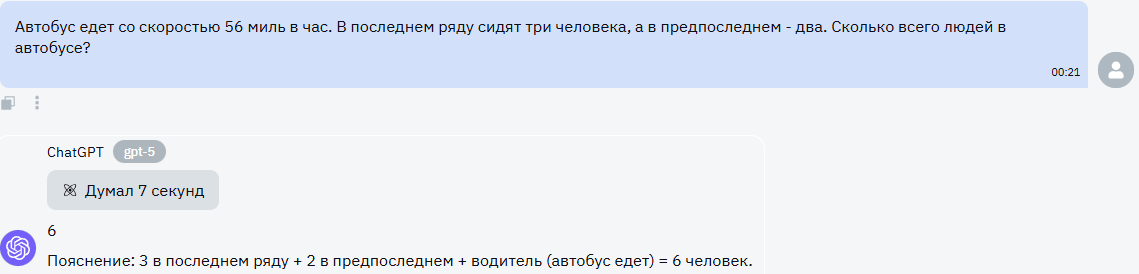
Хороший ответ - и соответствующий балл. Модель правильно сделала минимальный расчет, хотя и не учла неопределенность с другими пассажирами. По крайней мере, она не забыла про водителя.
Claude Opus 4.5
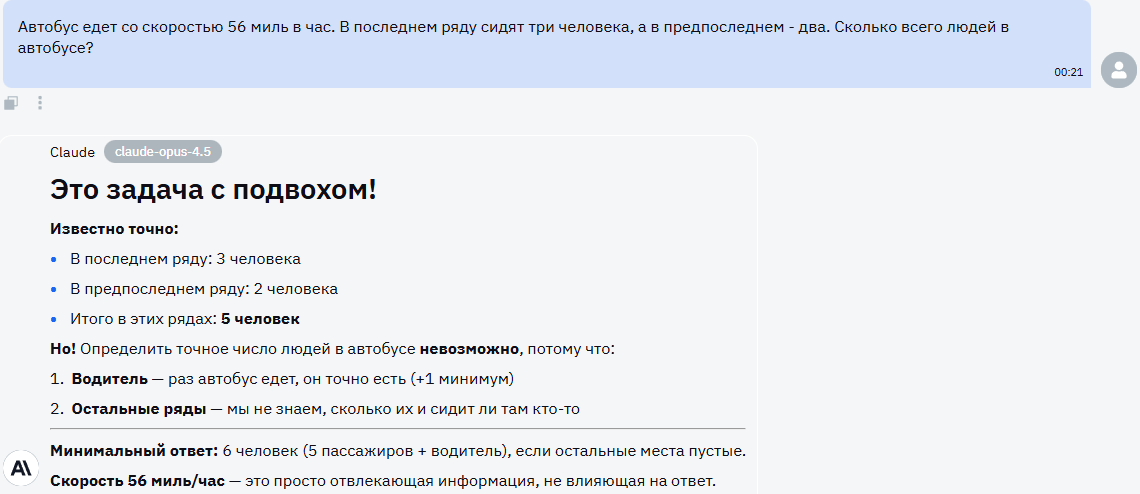
Opus 4.5 заметил подвох, четко его обозначил и дал минимально возможный ответ. Задача решена верно.
Gemini 3 Pro

В отличие от задания с игрой, здесь модель не подвела и дала ответ, аналогичный Opus 4.5. Снова максимальный балл.
Итог
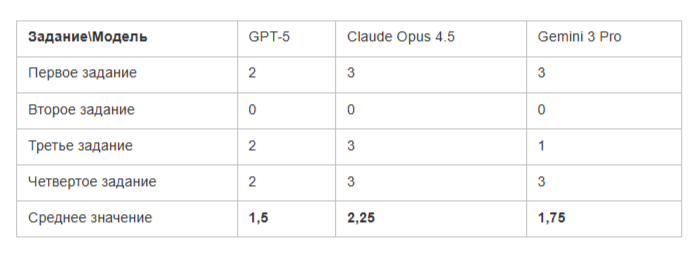
Согласно таблице, места распределились так: Claude Opus 4.5, Gemini 3 Pro, GPT-5. Если говорить прямо - от лучшей модели к худшей. Однако стоит отметить, что все участники продемонстрировали достойный уровень. Даже GPT-5 незначительно уступает конкурентам, а с учетом скорого выхода новой версии она может серьезно потеснить лидеров или встать на уровень с ними.