ChatGPT
17 марта 2026 г.
ChatGPT 5.4 Pro: обзор, бенчмарки, сравнение
Помните, как пару лет назад мы восхищались тем, что нейросеть может написать связный абзац? А год назад – что она осилила код без синтаксической ошибки? Сегодня планка взлетела так высоко, что уникальные способности моделей превращаются в стандартный пакет услуг.OpenAI выкатила GPT‑5.4 Pro. И если раньше слово “Pro” в названии часто означало просто “чуть больше токенов и подороже”, то теперь это действительно профессорский уровень. Модель берёт сложнейший тест ARC-AGI-2 с результатом 83,3% (против 54% у предшественницы), решает задачи из FrontierMath, которые ещё недавно казались крепостью для ИИ, и... случайно находит в интернете забытую научную статью 2011 года, чтобы срезать путь к ответу.В этом обзоре мы не только разбираем цифры бенчмарков (хотя они тут просто фантастические), но и устраиваем моделям настоящую проверку: от логической головоломки с серверами до полноценного стелс-симулятора на канвасе.

Компания OpenAI явила миру GPT-5.4 – новейшую модель, которую разработчики без лишней скромности назвали своим “самым мощным и эффективным инструментом для решения профессиональных задач”.Семейство не ограничивается стандартным вариантом (ChatGPT 5.4): пользователям предложена специализированная модель для глубоких раздумий (ChatGPT 5.4 Thinking) и версия, оптимизированная для сверхсложных задач и исследований (ChatGPT 5.4 Pro).GPT-5.4 – это не просто обновление, а серьезная эволюция предыдущих версий в плане логики и скорости. В OpenAI особо подчеркивают талант модели к созданию “сложных продуктов с длинным циклом”: от детализированных презентаций и замысловатых финансовых моделей до глубокого юридического анализа.Техническая составляющая тоже впечатляет: API-версия GPT-5.4 теперь способна держать в уме до 1 миллиона токенов. При этом модель стала заметно бережливее: там, где её предшественница GPT-5.2 тратила больше ресурсов, новинка справляется с теми же задачами, используя значительно меньшее количество токенов.OpenAI подчеркивает, что GPT-5.4 развивает идеи GPT-5.3 Codex, демонстрируя более уверенную хватку при работе с внешними инструментами, программными средами и повседневной офисной рутиной. В кодинговом тесте SWE-Bench Pro новинка не уступает GPT-5.3 Codex, при этом соображает она гораздо быстрее.> Любопытно, что Thinking-версии для 5.3 не существовало вовсе – были лишь варианты для кодинга (GPT-5.3 Codex) и обычная модель (GPT-5.3 Instant). Также вы не найдёте 5.1 Pro или 5.3 Pro. По словам разработчиков, такие скачки в нумерации призваны упростить выбор нужного инструмента.
Характеристики модели ChatGPT 5.4 Pro
Ввод: текст, изображения Вывод: текст Контекстное окно: 1 050 000 токенов (API-версия) Максимальный объем ответа: 128 000 токенов Логика и рассуждение: ★★★★★ Скорость: ★☆☆☆☆ Актуальность знаний: до 31 августа 2025 года Доступные инструменты: поиск в сети; работа с файлами; генерация изображений; внесение правок в код (apply patch); управление компьютером; MCP; поиск инструментов.Для тех, кто работает через API (или агрегатор нейросетей вроде BotHub), новая модель открывает невиданные горизонты: объем контекстного окна теперь достигает 1 050 000 токенов.Кроме того, разработчики внедрили технологию “поиска инструментов” (tool search), которая позволила сократить расход ресурсов на 47% в сложных тестах. Раньше при вызове модели в системный промпт приходилось буквально “заталкивать” описания всех доступных инструментов. Теперь же модель сама находит нужные спецификации инструментов по мере необходимости. Как итог, запросы стали быстрее, а эксплуатация систем с широким набором функций дешевле.Что говорят бенчмарки
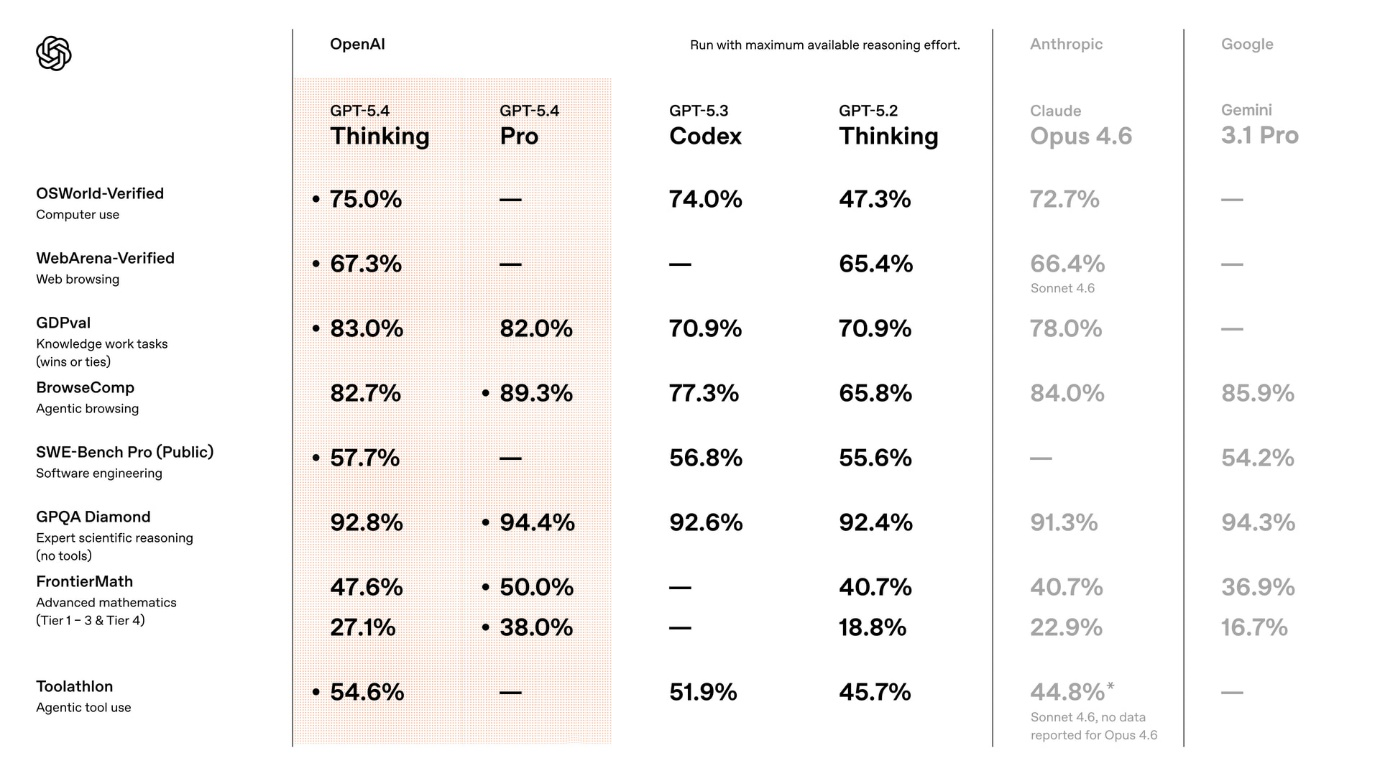
OpenAI явно готовила GPT-5.4 на роль идеального офисного сотрудника. Внутренний бенчмарк GDPval, имитирующий работу в 44 профессиях из девяти ключевых отраслей экономики, показал: модель справляется с задачами на уровне (или даже лучше) живых экспертов, набрав 83,0%. Для сравнения: у GPT-5.2 этот показатель составлял 70,9%. Что интересно, стандартная версия 5.4 Thinking в этом испытании внезапно обставила свою “профессиональную” сестру Pro.
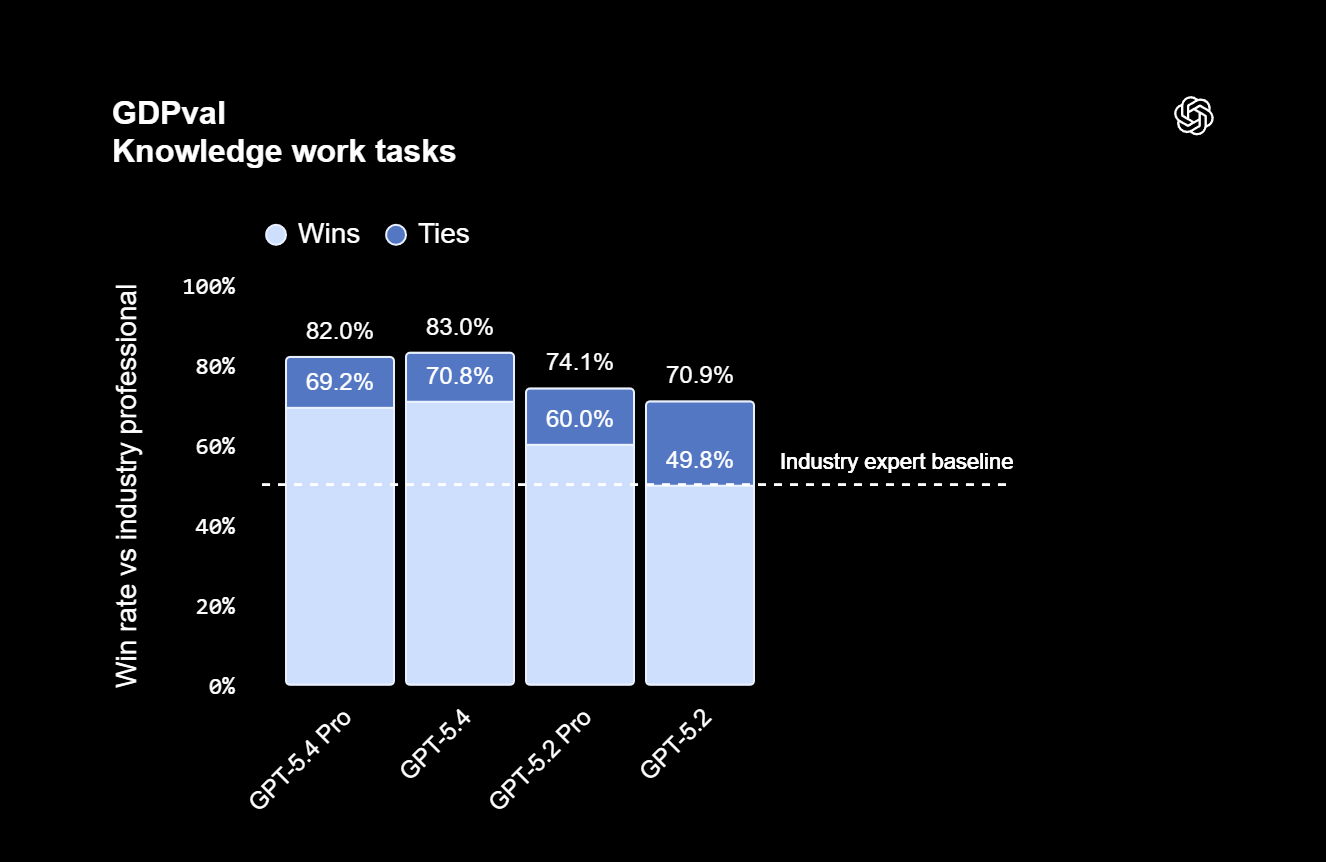
Академические тесты также подтверждают прогресс, особенно в области абстрактного мышления: GPT-5.4 Pro набрала 83,3% в сложнейшем тесте ARC-AGI-2, в то время как предыдущая GPT-5.2 Pro могла выдать лишь 54,2%.
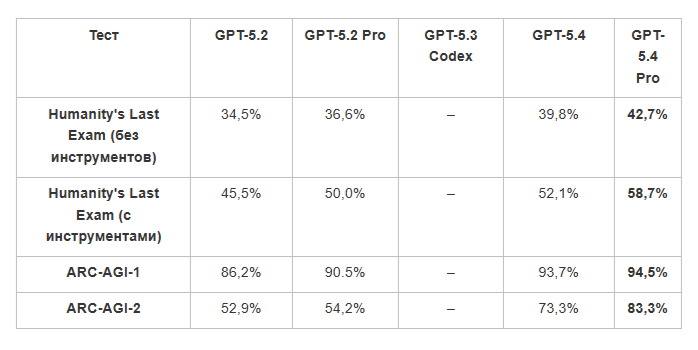
GPT-5.4 Pro берет новую высоту в FrontierMath
Еще в январе эксперты из компании Epoch AI, занимающейся тестированием искусственного интеллекта, отметили поразительный прогресс в FrontierMath. Предыдущая итерация модели, GPT-5.2 Pro, сумела одолеть 31% предложенных головоломок – внушительный скачок по сравнению с прежним рекордом в 19%.GPT-5.4 Pro продолжила это триумфальное шествие, взявшись за целый список сложнейших задач, составленный академическим сообществом. В зачете по первым трем уровням сложности (Tier 1–3) GPT-5.4 Pro справилась с половиной заданий, а на “гроссмейстерском” четвертом уровне (Tier 4) взяла планку в 38%.Анализ показал, что ИИ проявил “информационную смекалку”: модель отыскала научный препринт (черновик статьи, опубликованный до официальной проверки коллегами-учеными) 2011 года, который позволил ей срезать путь и миновать львиную долю вычислений, задуманных авторами теста. Речь идет о научной статье, которая в свое время так и не прошла через горнило официального рецензирования и затерялась в закромах интернета. Самому составителю задачи не было известно о существовании этой публикации.

Проект FrontierMath финансируется компанией OpenAI, которая обладает эксклюзивным доступом к расширенной базе данных: всем 290 задачам первых трех уровней сложности, а также к 28 из 48 задач четвертого уровня. Остальные задачи команда Epoch держит в секрете – эта контрольная выборка служит для беспристрастной проверки моделей.Таким образом, на сегодняшний день совместными усилиями разных моделей удалось расколоть уже 42% задач (20 из 48) самого сложного, IV уровня. Вспомните: всего год назад пределом мечтаний (у той же o3) были 2%. Сегодня GPT 5.4 Pro берет планку в 38%. Лучший результат среди систем с открытым кодом – 4,2% у Kimi K2.5. Разрыв стал девятикратным, пропасть только растет, и свободное сообщество разработчиков уже даже не видит габаритных огней уходящего вперед лидера.
Управление рабочим столом
Разработчикам впервые удалось объединить в одной модели мастерство программирования, глубину логического мышления и умение распоряжаться ресурсами компьютера.GPT-5.4 способна самостоятельно писать код на Playwright, считывать скриншоты и имитировать действия пользователя, нажимая клавиши и перемещая курсор мыши. Вы можете гибко настраивая правила подтверждения операций в зависимости от допустимых рисков.Кроме того, заявлен качественный скачок в умении нейросети самостоятельно бороздить просторы интернета. В испытании OSWorld-Verified (навигация по рабочему столу с помощью скриншотов, мыши и клавиатуры) GPT-5.4 показала успех в 75% случаев, против 47,3% у GPT-5.2. Средний результат человека в этом тесте составляет 72,4% (ИИ официально переиграл человеков).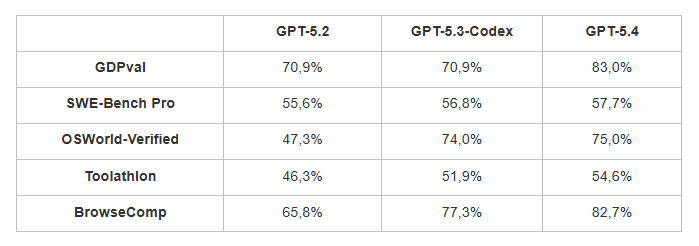
разыскать труднодоступные данные, GPT-5.4 набрала 82,7%, GPT-5.4 Pro – 89,3% (против 65,8% у версии 5.2).
CritPt – (Complex Research using Integrated Thinking – Physics Test) – это бенчмарк, созданный для тестирования LLM на неопубликованных задачах исследовательского уровня. Он охватывает широкий спектр современной физики: от физики конденсированного состояния, квантовых систем, атомной, молекулярной и оптической до астрофизики, физики высоких энергий, математической и статистической, а также ядерной физики, нелинейной динамики, гидродинамики и биофизики.
Прорыв в физике
GPT-5.4 Pro (на макс. уровне рассуждений xhigh) показала феноменальный результат в тесте CritPt, прибавив сразу 10 пунктов и достигнув 30%.Чтобы оценить масштаб этого достижения, стоит вспомнить: когда в ноябре 2025-го этот тест только появился, потолком была отметка в 9% (тогда рекорд принадлежал Gemini 3 Pro Preview). Не прошло и четырех месяцев, как лучший результат взлетел более чем втрое, достигнув 30%. Картина меняется буквально на глазах.CritPt – (Complex Research using Integrated Thinking – Physics Test) – это бенчмарк, созданный для тестирования LLM на неопубликованных задачах исследовательского уровня. Он охватывает широкий спектр современной физики: от физики конденсированного состояния, квантовых систем, атомной, молекулярной и оптической до астрофизики, физики высоких энергий, математической и статистической, а также ядерной физики, нелинейной динамики, гидродинамики и биофизики.
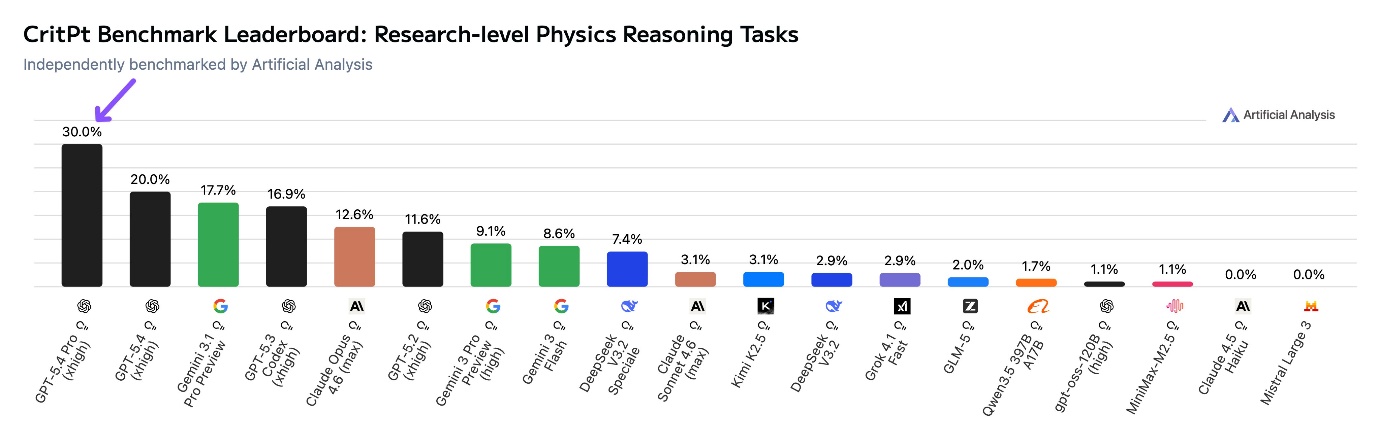
CritPt включает 71 комплексную задачу, каждая из которых имитирует исследовательский проект. Для более детального анализа каждая из задач разбита на контрольные этапы (всего 190 промежуточных заданий). Все условия созданы с нуля пятьюдесятью практикующими физиками на основе их собственных научных работ. Каждое задание выверено вручную, ответы защищены от угадывания и проверяется автоматизированной системой.
Задача 1: миграция серверов
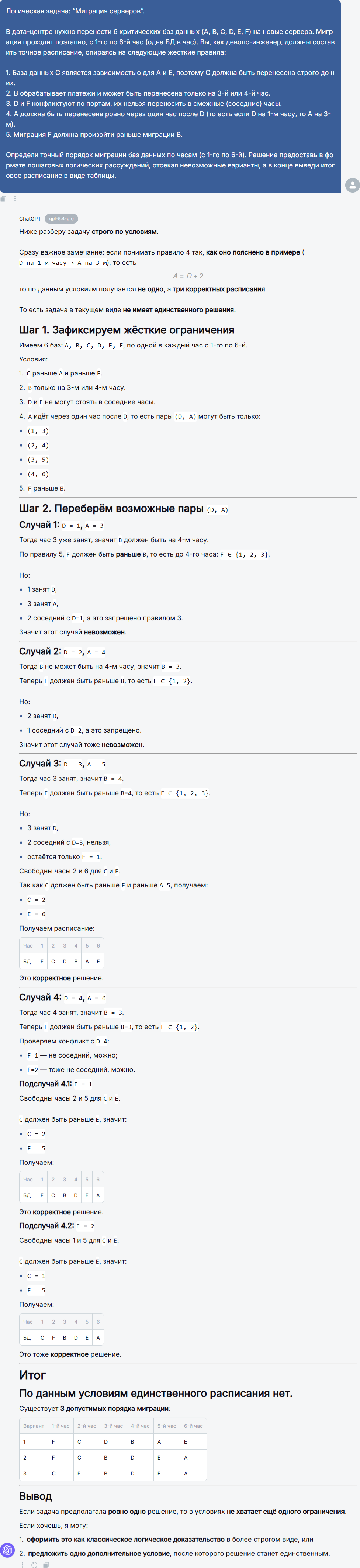
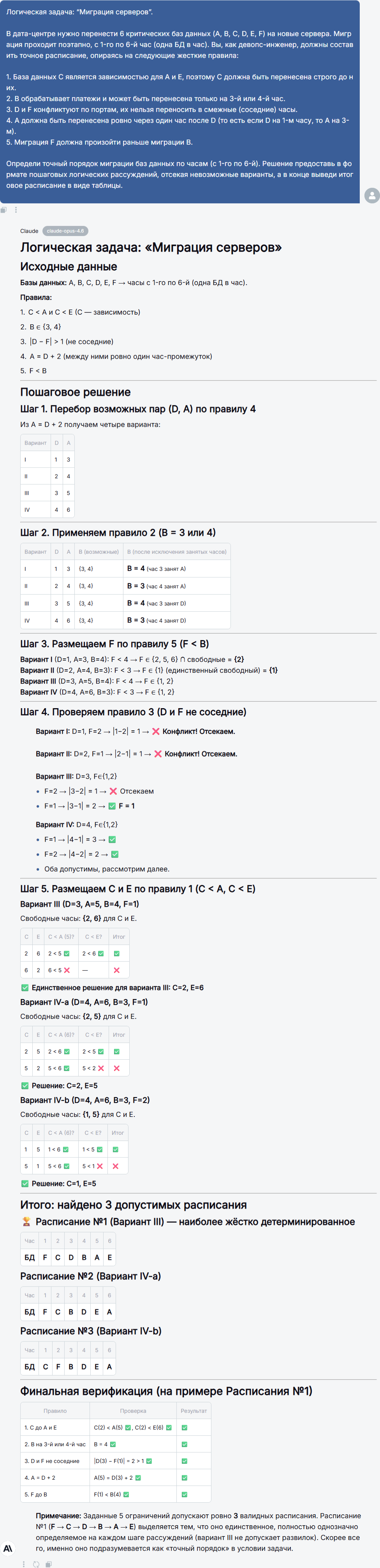
Начнём с разминки для ума. Первый промпт – сложная логическая задача на составление расписания:Логическая задача: “Миграция серверов”. В дата-центре нужно перенести 6 критических баз данных (A, B, C, D, E, F) на новые сервера. Миграция проходит поэтапно, с 1-го по 6-й час (одна БД в час). Вы, как девопс-инженер, должны составить точное расписание, опираясь на следующие жесткие правила: 1. База данных C является зависимостью для A и E, поэтому C должна быть перенесена строго до них. 2. B обрабатывает платежи и может быть перенесена только на 3-й или 4-й час. 3. D и F конфликтуют по портам, их нельзя переносить в смежные (соседние) часы. 4. A должна быть перенесена ровно через один час после D (то есть если D на 1-м часу, то A на 3-м). 5. Миграция F должна произойти раньше миграции B. Определи точный порядок миграции баз данных по часам (с 1-го по 6-й). Решение предоставь в формате пошаговых логических рассуждений, отсекая невозможные варианты, а в конце выведи итоговое расписание в виде таблицы.Правила связаны между собой, и только комбинаторный перебор с отсечением приводит к корректному ответу. Для человека это несложное упражнение на внимательность, а для нейросетей – отличный тест на способность строить цепочки логических выводов и учитывать все ограничения одновременно.Такие головоломки хороши тем, что в них нет места плавающим формулировкам: либо расписание составлено верно, либо нет. А если условие допускает несколько решений, модель должна либо выбрать одно (если того требует промпт), либо честно перечислить все варианты.Посмотрим, как справились наши модели!
ChatGPT 5.4 Pro
Claude Opus 4.6
Gemini 3.1 Pro

- ChatGPT 5.4 Pro подошёл к задаче с математической скрупулёзностью: он аккуратно перебрал все возможные пары для D и A, проверил каждый вариант на совместимость с позицией B, затем разместил F с учётом запрета соседства и, наконец, расставил C и E. В результате модель обнаружила, что условия не задают единственного расписания, и выдала три допустимых варианта. Такой подход демонстрирует не только умение рассуждать, но и честность: если задача имеет множество решений, не стоит навязывать одно.
- Claude Opus 4.6 действовал схожим образом, но его решение выглядит более структурированным – с таблицами, пошаговой верификацией и итоговым сравнением вариантов. Он тоже пришёл к трём расписаниям, но дополнительно отметил, что одно из них (F → C → D → B → A → E) получается наиболее детерминированным на каждом шаге, и предположил, что авторы задачи, скорее всего, имели в виду именно его. При этом Opus честно перечислил все три решения, не скрывая неоднозначности.
- Gemini 3.1 Pro пошёл другим путём: вместо полного перебора он сразу отсек часть вариантов, опираясь на эвристику “В строгих архитектурных задачах правильный путь ведёт к единственному решению”. В итоге модель выдала ровно одно расписание, совпадающее с первым вариантом у конкурентов. Хотя ответ формально верный (это одно из допустимых решений), Gemini проигнорировал другие возможности, которые следуют из условий.
Задача 2: стелс-игра
От логических абстракций перейдём к чему-то более осязаемому. Что если попросить модели сверстать не просто веб-страницу, а полноценную игру? Задачу я выбрал заведомо сложную: стелс-симулятор с процедурной генерацией, динамическим освещением и толпой охранников.Создай веб-интерактивность на JS и canvas (один HTML-файл): тактический стелс-симулятор с динамическим освещением. Пусть будет вид 2D top-down, где игрок перемещается по процедурно сгенерированному лабиринту сложной формы (сгенерируй его алгоритмом клеточного автомата или BSP-деревом). Ключевая механика – реалистичная видимость и тени (Raycasting / Line of sight): • Игрок видит только то, что находится в зоне его обзора – сектор в 120° по направлению курсора мыши. • Все остальное скрыто в “тумане войны”. • Свет от игрока должен корректно упираться в стены лабиринта, создавая жесткие динамические тени. Используй математику пересечения лучей и отрезков для построения полигона видимости. • По лабиринту патрулируют 7 охранников. У них тоже есть свои конусы зрения (желтого цвета), которые подсвечивают пространство. Охранники ходят по цикличным маршрутам. • Если игрок попадает в луч света охранника, цвет экрана кратковременно вспыхивает красным, и игра перезапускается с новой генерацией лабиринта. Управление – WASD и клавиши-стрелки. Физика должна быть плавной, игрок не должен проваливаться сквозь стены (AABB collision). Текстуры и формы объектов пусть генерируются процедурно при открытии HTML-файла в браузере. Цвет стен не чёрный. Персонажи рисуются векторными фигурами либо пиксель-артом, для их передвижения применяются анимации.Объём кода здесь легко переваливает за 20–30 тысяч символов, и любая опечатка в математике лучей или коллизий отправит весь замысел в красный океан консоли. Справится ли ИИ с такой композицией? Забегая вперёд – да, но с очень разным качеством исполнения.Результаты на CodePen:Это отличный стресс-тест для кодирующих способностей нейросетей. Поначалу кажется, что все три результата похожи: мрачные лабиринты, жёлтые конусы света, квадратный игрок. Но при более близком знакомстве различия становятся заметными.
- Claude Opus 4.6 традиционно оказался молодцом. Игра выглядит именно так, как и задумывалось: плавная, атмосферная, с деталями. Мало того что анимации конечностей у персонажей шевелятся при ходьбе (это было в промпте), так охранники ещё и ведут себя пугающе реалистично: медленно patрулируют, а в некоторых точках останавливаются и озираются по сторонам. Этого в задании не было – модель сама додумалась добавить!
- ChatGPT 5.4 Pro выдал не самый лучший результат. Несмотря на то что на генерацию он потратил заметно больше времени и токенов, результат получился сыроватым. Главная претензия – масштаб. Действие происходит на огромном пустом пространстве с редкими стенами, что напрочь убивает стелс-механику: прятаться там просто негде. Враги поворачиваются мгновенно, без всякой анимации, словно в некоторых современных soulslike.
- Gemini 3.1 Pro расположился где-то посередине. Визуально его версия очень похожа на творение Opus: те же клеточки, те же шевелящиеся конечности. Но к геометрии обзора есть вопросы. Конус видимости иногда обрезается по какой-то странной прямой линии, а в местах наложения вражеских лучей разобрать, где опасность, а где свои, становится невозможно. В самый напряжённый момент игры ты просто не видишь нужной информации – для стелс-симулятора это критично.